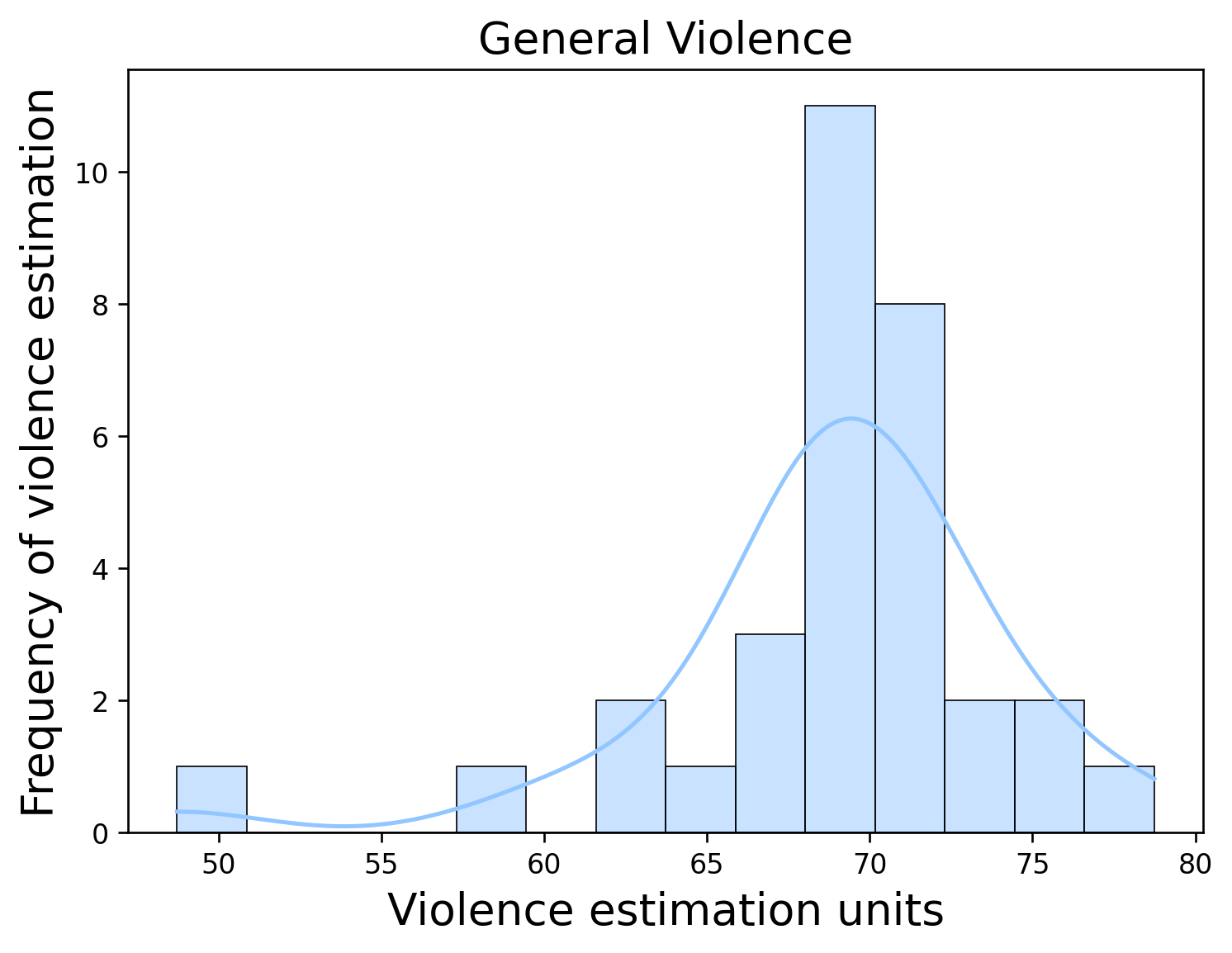
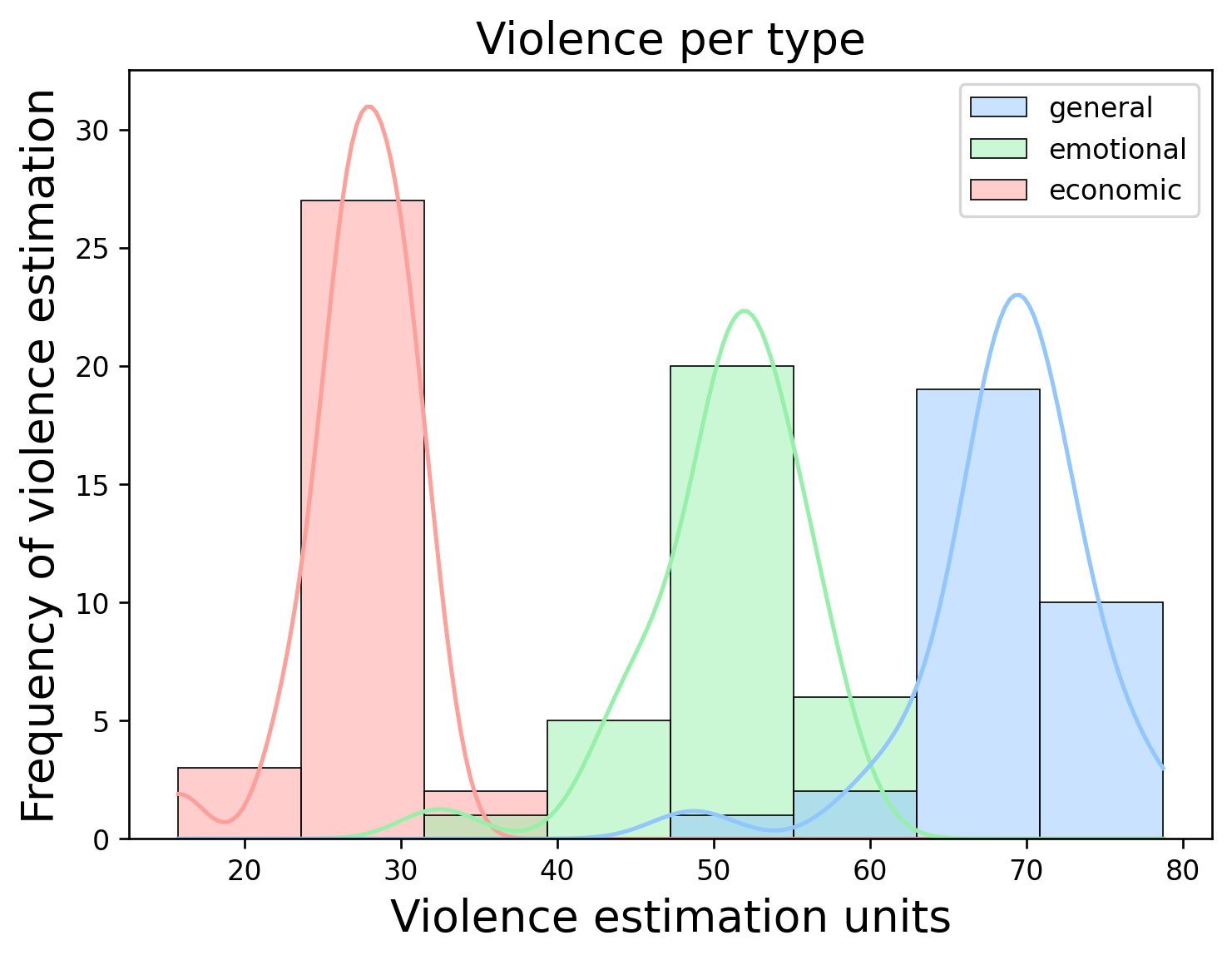
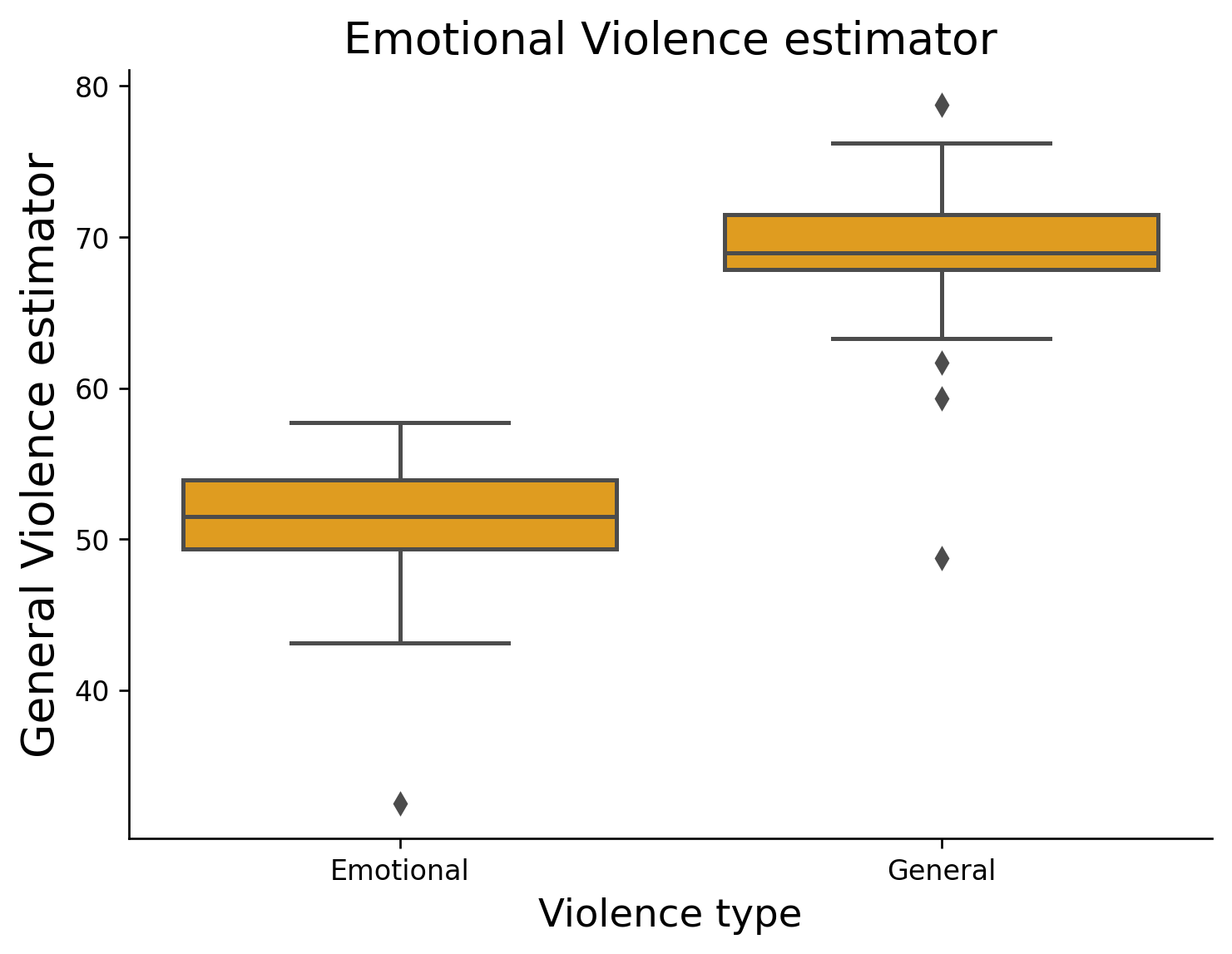
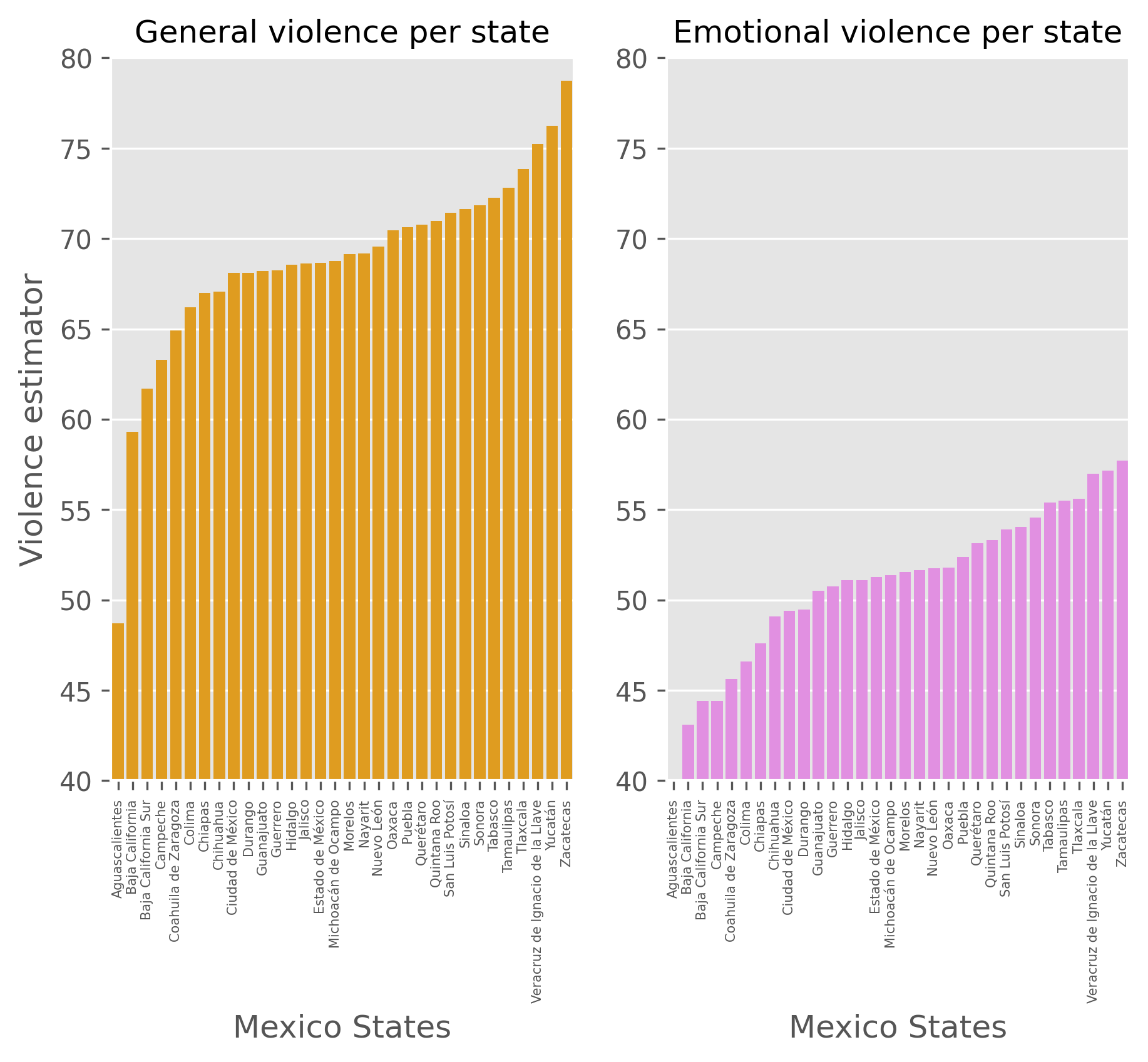
[Text(0, 0, 'Aguascalientes'),
Text(1, 0, 'Baja California'),
Text(2, 0, 'Baja California Sur'),
Text(3, 0, 'Campeche'),
Text(4, 0, 'Coahuila de Zaragoza'),
Text(5, 0, 'Colima'),
Text(6, 0, 'Chiapas'),
Text(7, 0, 'Chihuahua'),
Text(8, 0, 'Ciudad de México'),
Text(9, 0, 'Durango'),
Text(10, 0, 'Guanajuato'),
Text(11, 0, 'Guerrero'),
Text(12, 0, 'Hidalgo'),
Text(13, 0, 'Jalisco'),
Text(14, 0, 'Estado de México'),
Text(15, 0, 'Michoacán de Ocampo'),
Text(16, 0, 'Morelos'),
Text(17, 0, 'Nayarit'),
Text(18, 0, 'Nuevo León'),
Text(19, 0, 'Oaxaca'),
Text(20, 0, 'Puebla'),
Text(21, 0, 'Querétaro'),
Text(22, 0, 'Quintana Roo'),
Text(23, 0, 'San Luis Potosí'),
Text(24, 0, 'Sinaloa'),
Text(25, 0, 'Sonora'),
Text(26, 0, 'Tabasco'),
Text(27, 0, 'Tamaulipas'),
Text(28, 0, 'Tlaxcala'),
Text(29, 0, 'Veracruz de Ignacio de la Llave'),
Text(30, 0, 'Yucatán'),
Text(31, 0, 'Zacatecas')]