SVMs will be introduced on this page to continue the task of training a supervised classifier to automatically detect if a tweet is misogynistic or not. This model will be compared to past Naive Bayes results.
Model
Support Vector Machines is a supervised learning model. It’s objective is to maximize the distance between the two categories on an N-dimensional space by finding a hyperplane that does so. The model maps training examples as points in a vector space separated by categories. The data we want to predict is projected to fit into one of the categories by being mapped into that same space.
SVM is a flexible model, by default the model will perform a “linear” separation of the data points, additionally the model can efficiently perform a non-linear classification through a “kernel” function which, depending on the one we select, might provide a better fit for our data and finally, improve the accuracy of the model.
Evaluation Metrics
The results of the model will be compared to Naive Bayes in terms of accuracy, computational efficiency and a deeper look of results.
Implementation
Language model
To represent the text a Bag Of Words model is implemented with the TF-IDF measure for the appearance of each word.
Implementation with SKlearn
Although the text was cleaned and stemmed it contains more than a 10,000 words. Given this, without removing features the SVC model was not able to run in a local computer environment.
SKlearn documentation explains the model implementation is based on libsvm and fitting time scales at least quadratically with the number of samples and may be impractical beyond tens of thousands of samples, which is our case. It suggests to use LinearSVC which will be used to perform the next task.
Talking about feature selection on text data, there are multiple techniques to clean the data but it is not possible to perform an specific feature selection of certain words since it would lead to a loss of context while predicting. We will test this assumption by using a Variance Threshold Feature Selection technique and measure the output of our model in comparison with no feature selection.
Code
from sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.svm import SVCfrom sklearn.metrics import ConfusionMatrixDisplay, accuracy_score, recall_scorefrom sklearn.metrics import confusion_matrixfrom tabnanny import checkfrom nltk.tokenize import TweetTokenizerimport reimport pandas as pdimport seaborn as snsimport numpy as npimport matplotlib.pyplot as pltimport matplotlib.stylematplotlib.style.use('seaborn-pastel')from nltk.tokenize import RegexpTokenizerfrom wordcloud import WordCloud, STOPWORDSimport matplotlib.pyplot as pltimport seaborn as snsimport nltkfrom nltk.probability import FreqDistfrom nltk.stem import PorterStemmerdf = pd.read_csv('data/clean_set.csv', encoding='latin1')df.head(5)
text
label
0
?? no s si das ms pena t o tu terrible ortogr...
0
1
Cuando todo se va al infierno, la gente que e...
0
2
- En 1800 nace #NatTurner, el esclavo rebelde ...
0
3
entre muchas otras Muere el 6 de nov 2015 ??...
0
4
era la maldicin de muchas familias.
0
Code
#check balance of the classesdef check_balance(df):print(df.label.value_counts())check_balance(df)print(len(df["label"]))
0 5017
1 5012
Name: label, dtype: int64
10029
Classes are balanced and even though the data points compose a small set the number of features 10029 makes the efficiency drop
Code
#preprocessing techniquesfrom nltk.corpus import stopwordsdef clean(df): ps = PorterStemmer() email_re =r"""(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])""" replace = [ (r"<a[^>]*>(.*?)</a>", " url"), (email_re, "email"), (r"@[a-zA-Z0-9_]{0,15}", " user"), (r"_[a-zA-Z0-9_]{0,15}", " user"), (r"#\w*[a-zA-Z]\w*", " hashtag"), (r"(?<=\d),(?=\d)", ""), (r"\d+", "numbr"), (r"[\t\n\r\*\.\@\,\-\/]", " "), (r"\s+", " "), (r'[^\w\s]', ''), (r'/(.)(?=.*\1)/g', "") ]for repl in replace: clean_text = [re.sub(repl[0], repl[1], str(text))for text in df["text"]] df["clean_text"] = clean_text tokenizer = RegexpTokenizer(r'\w+') clean_text = [] stop_words =set(stopwords.words('spanish')) stop_words = stop_words -set(["el","él","ellas","ella","lo","la"])for tweets in df["clean_text"]: words = tokenizer.tokenize(tweets) lower_words = [ps.stem(w.lower()) for w in words if w notin stop_words] clean_text.append(" ".join(lower_words)) df["tokenized_text"] = clean_text# Saving dataframe to csv for R script df.to_csv("clean_data.csv")return dfdef vectorize(df): vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(df["tokenized_text"]) X = X.toarray()return(X)def split_data(X,y): X_train, X_test, y_train, y_test = train_test_split( X, y,test_size=0.30)return X_train, X_test, y_train, y_testdf = clean(df)X = vectorize(df)print(X.shape)
(10029, 14426)
Applying the preprocessing techniques to reduce features as much as possible
Code
model = SVC(kernel ="linear")
Testing with Variance Threshold Feature selection technique
Code
from sklearn.feature_selection import VarianceThresholdprint(X.shape)selector = VarianceThreshold(threshold=.001)X_vr = selector.fit_transform(X)print(X_vr.shape)
(10029, 14426)
(10029, 86)
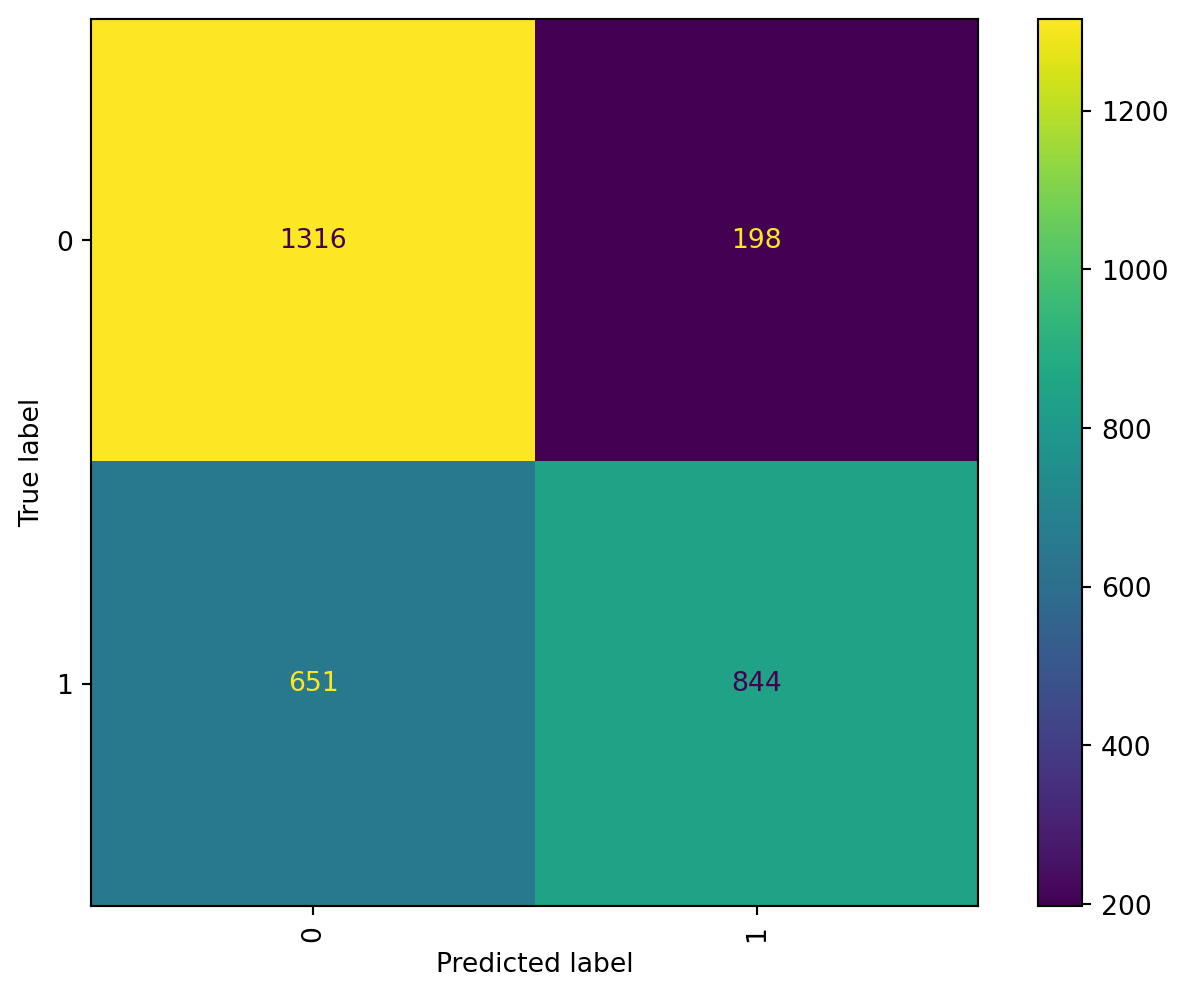
We can see how the features were reduced from 14,693 to 80 based on the threshold equal to .001, by looking at this value we can imply the model will be biased by truncating such a big ammount of words, but the training will be developed to understand the perfomance of the model with this set.
# Save the results in a data frame.from sklearn.metrics import classification_report, confusion_matrixclf_report_linear = classification_report(y_test, y_pred, output_dict=True)pd.DataFrame(clf_report_linear).transpose()
The accuracy of the model might not be “bad” but if we understand how the data was transformed we can certainly say the data and thus, the model are biased.
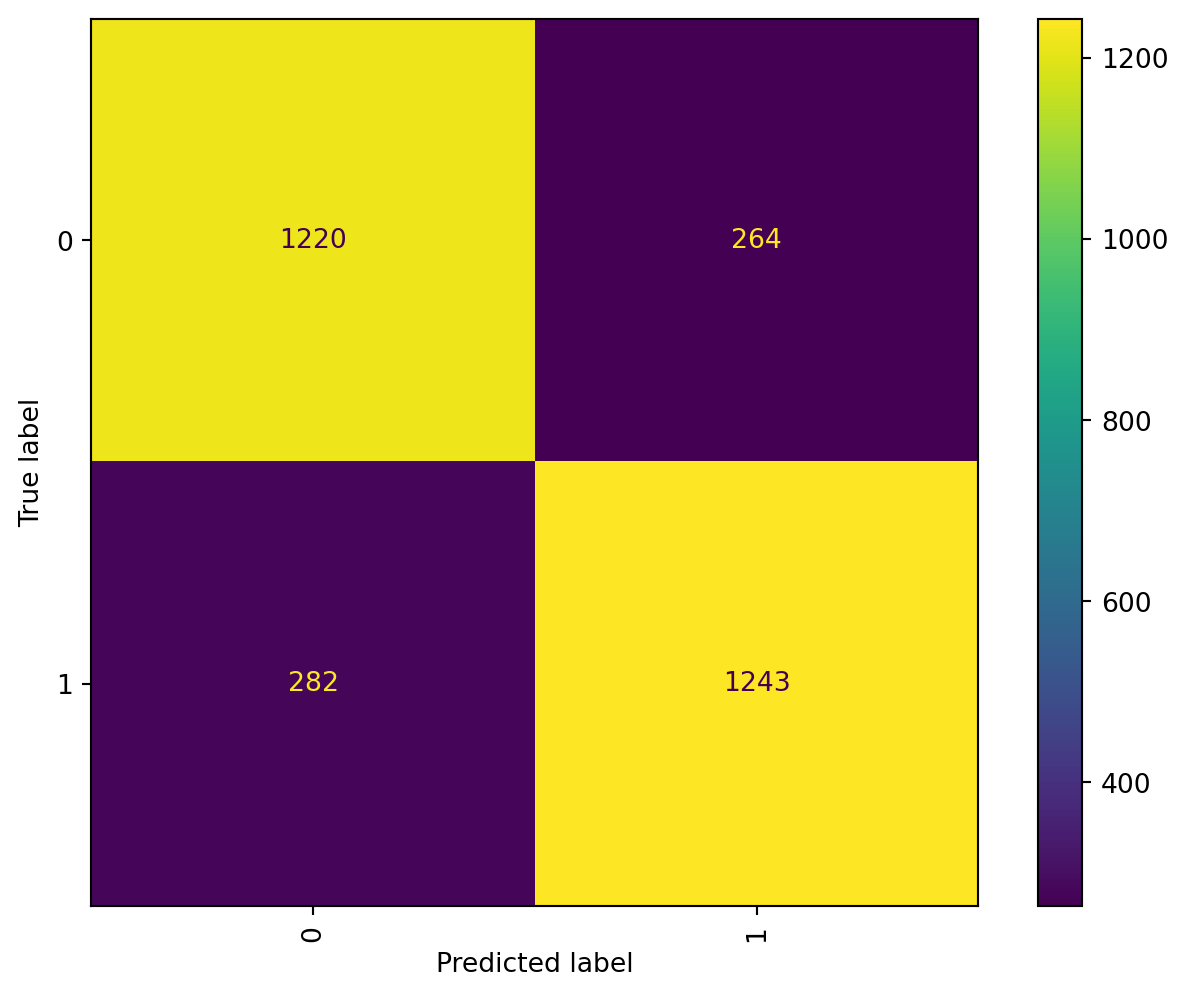
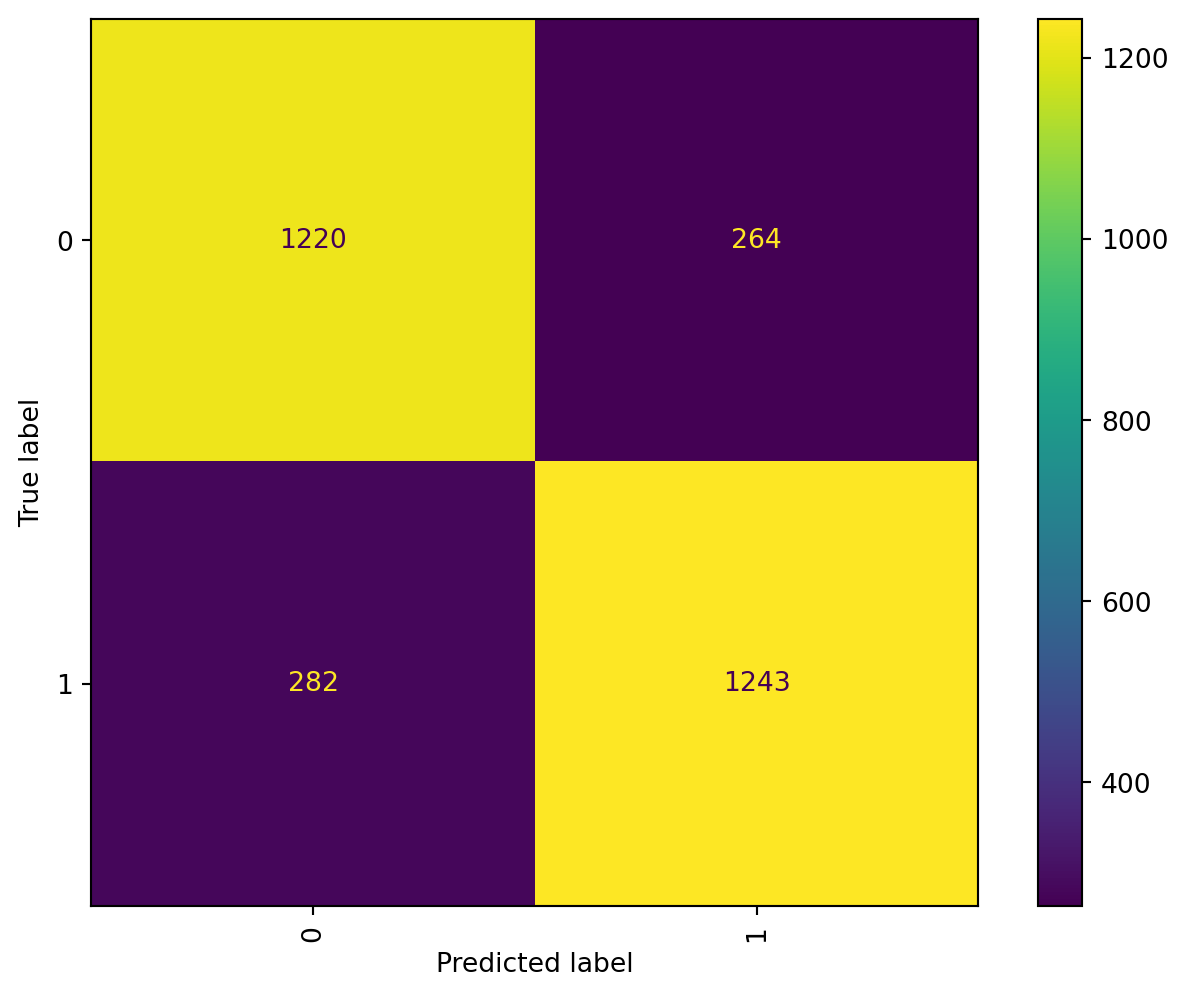
We will implement a model capable of fitting the whole features.
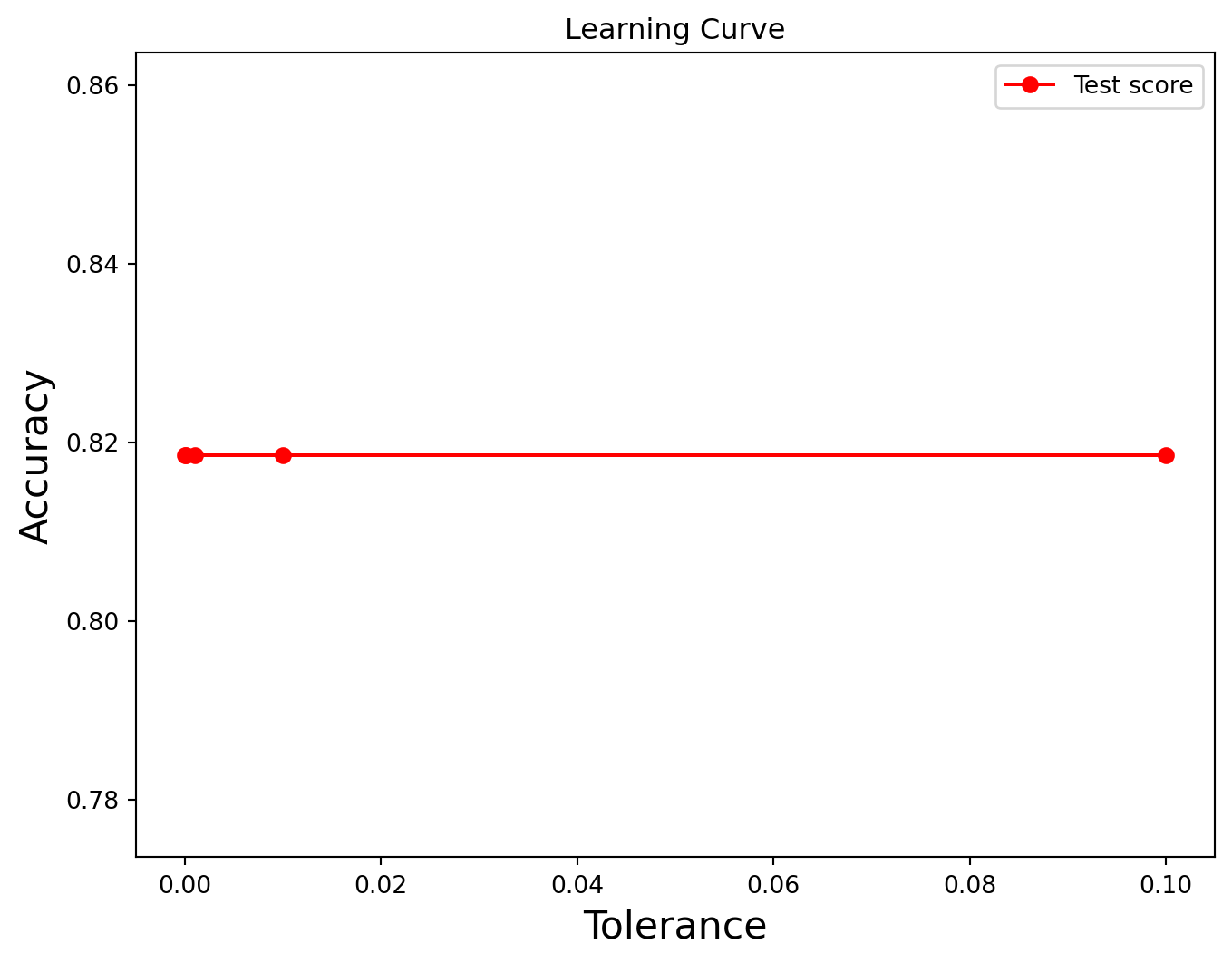
model.fit(X_train, y_train)y_pred = model.predict(X_test)test_results = []tolerance =[1e-1,1e-2,1e-3,1e-4,1e-5]for i in tolerance: model = LinearSVC(random_state=0, tol=i) model = model.fit(X_train,y_train) yp_test=model.predict(X_test) test_results.append(accuracy_score(y_test, yp_test))plt.subplots(1, figsize=(8, 6))plt.plot(tolerance, test_results, label="Test score", color="red",marker="o")plt.title("Learning Curve")plt.xlabel("Tolerance",fontsize=16), plt.ylabel("Accuracy",fontsize=16), plt.legend(loc="best")plt.show()
We can see an increase of accuracy after the tolerance gets closer to .10, although by looking at the labels we can see the accuracy increases from 83.18% to 83.21% which is an smaller change but we will keep that hyperparameter.
Finally, a random classifier will be trained to compare this results with a baseline metric
Code
#random classifierimport numpy as npimport randomfrom collections import Counterfrom sklearn.metrics import accuracy_scorefrom sklearn.metrics import precision_recall_fscore_supportdef random_classifier(y_data): ypred=[] max_label=np.max(y_data);#print(max_label)for i inrange(0,len(y_data)): ypred.append(int(np.floor((max_label+1)*np.random.uniform(0,1))))print("count of prediction:",Counter(ypred).values()) # counts the elements' frequencyprint("probability of prediction:",np.fromiter(Counter(ypred).values(),dtype=float)/len(y_data)) # counts the elements' frequencyprint("accuracy",accuracy_score(y_data, ypred))print("precision, recall, fscore,support",precision_recall_fscore_support(y_data,ypred))print("\nBINARY CLASS: ENDIREH data")random_classifier(y_train)
BINARY CLASS: ENDIREH data
count of prediction: dict_values([3498, 3522])
probability of prediction: [0.4982906 0.5017094]
accuracy 0.506980056980057
precision, recall, fscore,support (array([0.51022147, 0.50371641]), array([0.50863289, 0.50530542]), array([0.50942594, 0.50450966]), array([3533, 3487], dtype=int64))
Conclusion
The accuracy of our random classifier is around 51.69 % in comparison with our best tuned model there is an increase of more than 30% by training without feature selection.
As conclusion it is important to understand the nature of predicting texts. We cannot do the same techniques to text data given the nature of it’s modelling. As shown through our experiments, removing important features or words might not drop the accuracy of the model but we can be sure the model is not collecting and modelling the information as it should.
Modelling data text, specially sentiment is a task under the Natural Language Processing field that has developed better models for automatic emotion or detection.
As next steps for the data modelling it would be interesting to use the huge amount of features to train a model more suitable for this kind of data, for example, word embeddings, neural network modelling.
Finally, as a conclusion for the SVM model, we demonstrated the importance of the implementation of each model and the computational cost behind it. In comparison to our last model, Naive Bayes, the models performed similar and Naive Bayes had a lower time of processing. Although once again, that might not be related to the efficiency of the model but rather the biased modelling of our data.