For an gathering our data this project focuses on multiple sections of the survey which contain the TRUE or FALSE answers to experienced violent situations. The largest section “TVIV” is composed by 122,646 objects with 35 indicators each. The objects are the answers or what we call “rows” of data and the 35 indicators are questions to violent situations or “columns”.
As mentioned before, the indicator is a boolean variable that, based on an ENDIREH key dictionary, it will indicate if the answer to that question elevates the experienced violence metric of the person answering the survey.
INEGI has provided ENDIREH results on multiple type files such as CSV, DTA, DBF, SAV, RData. All of them that can be downloaded from their webpage INEGI. For this project the Rstat data type was downloaded to collect the information.
INEGI also provides a manual to understand and manipulate the data set.
As mentioned before, the dataset is composed by 28 tables with all the information retrieved by the survey. All the information is presented by the acts of violence experienced in the school, work, community and family settings. Tables are labeled with a combination of letters related to the title of the section for example “Tabla de la información de la vivienda (TVIV)” which translates to “Housing information table” and contains the residence characteristics, the number of persons living on it and the number of people sharing the costs of space.
As seen on the past image the tables contain different type of data values, for example string such as “Aguascalientes” to identify the state of origin of the women, and integers that will act as labels for the multiple question answers to specific questions.
[Entity relation model, author: INEGI]
Twitter Data
For the implementation of this project 2 APIs were used to collect data from twitter, one through python using the Tweepy API which is an open-source Python package that gives access to the Twitter API and the second one through R using the Rtweet API An implementation of calls designed to collect and organize Twitter data via Twitter’s REST API.
For the first stage of this project 10000 tweets were collected through Tweepy and 1000 through Rtweet both searches were querying tweets with the word “Feminista” (feminist). For this stage the R script outputs a txt file and generates a worldcloud to do a simple analysis of the words within the collected set and the Python script collects metadata from the tweet such as “id” and “creation_date”, the information is stored on a csv file.
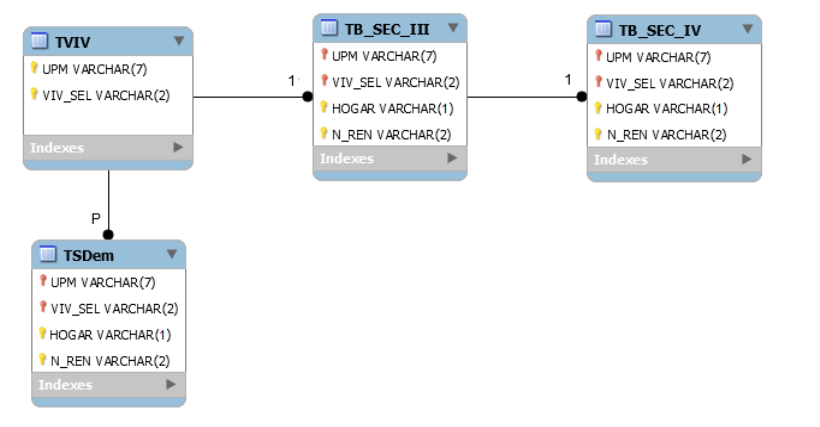 [Entity relation model, author: INEGI]
[Entity relation model, author: INEGI]