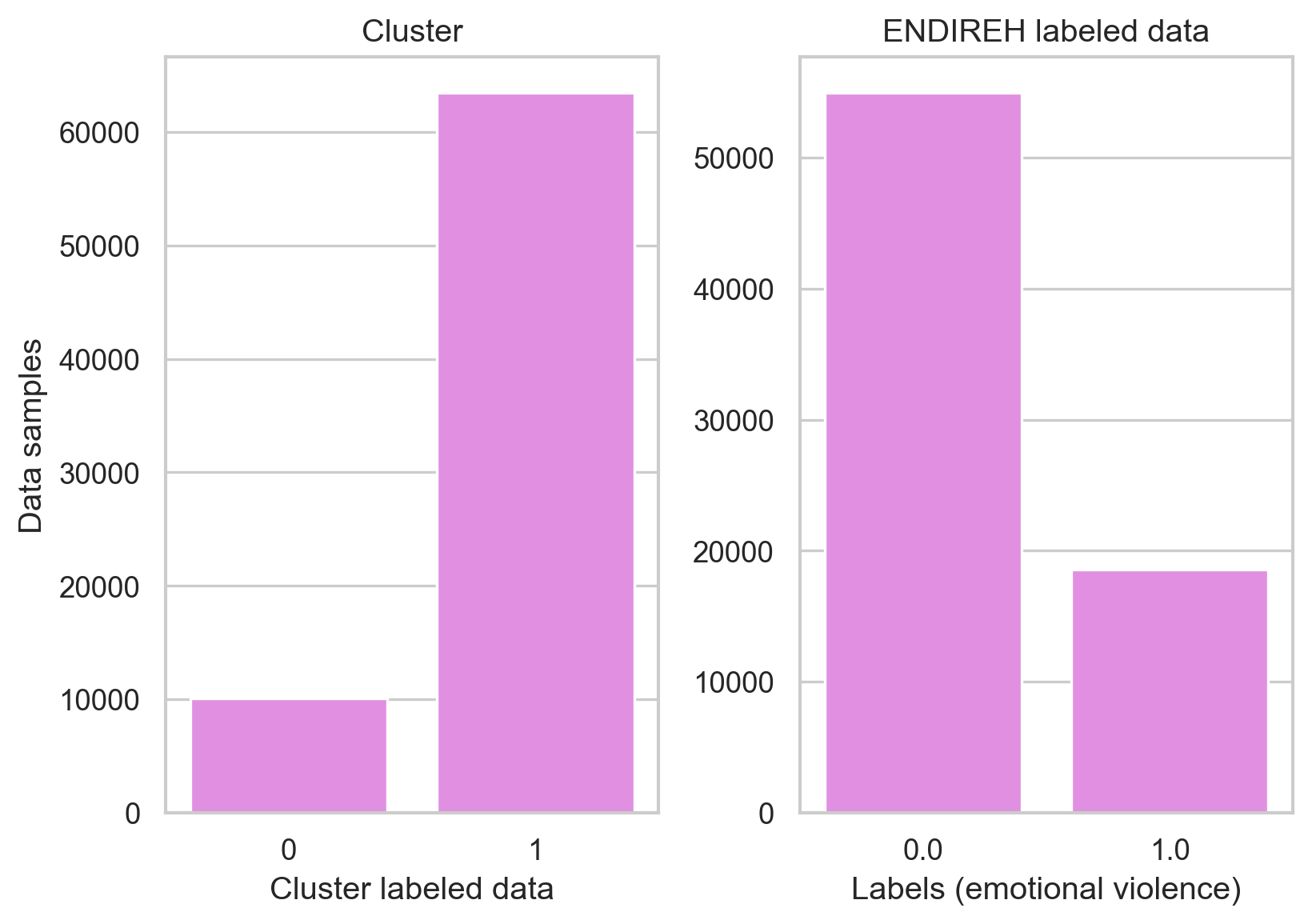
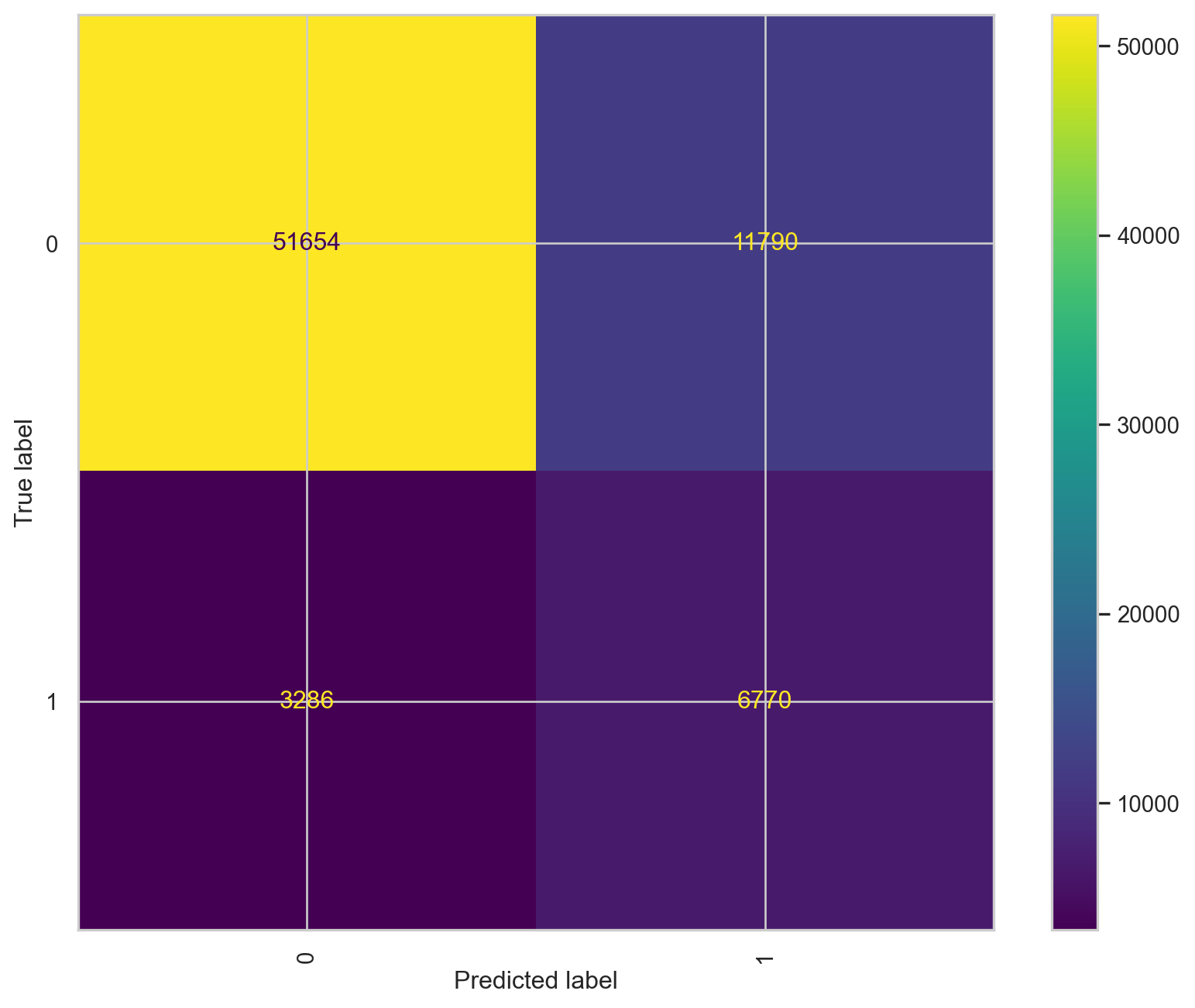
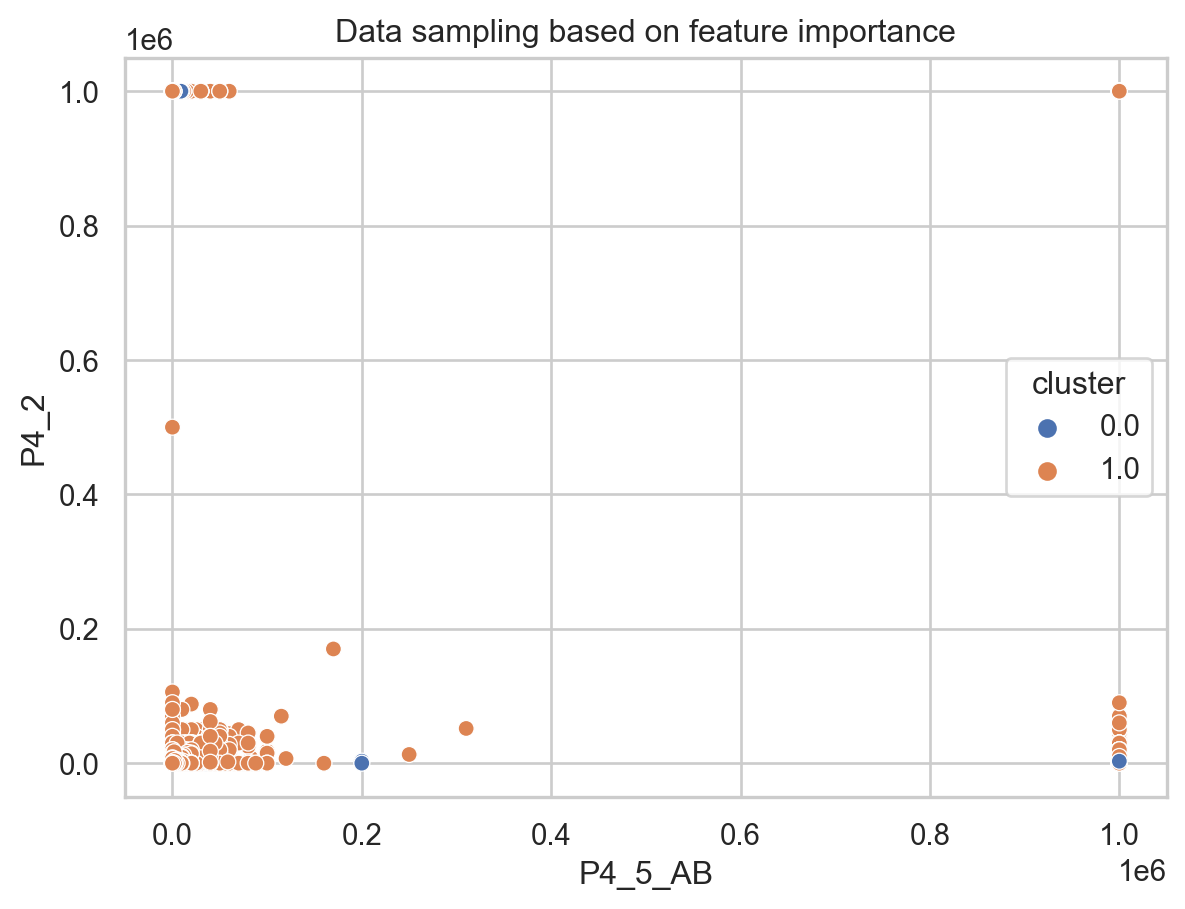
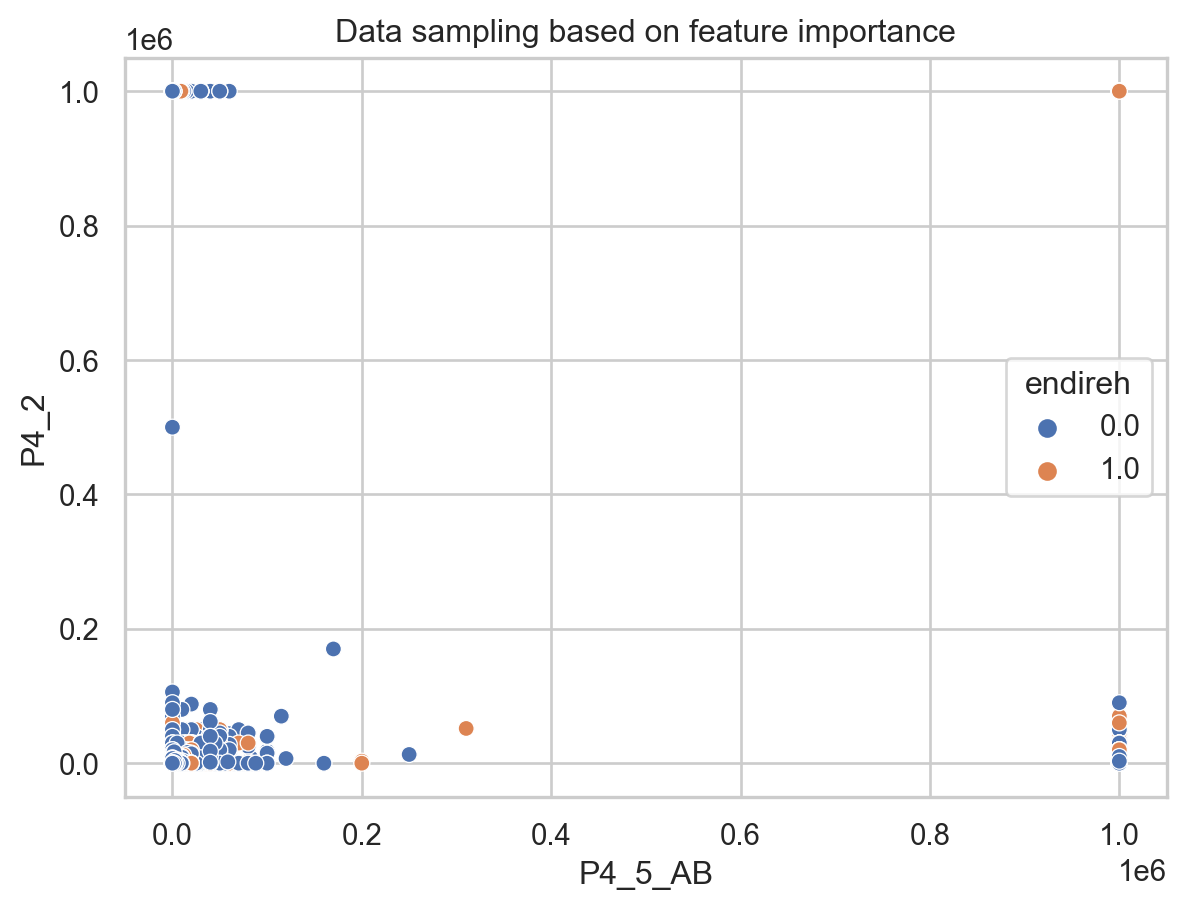
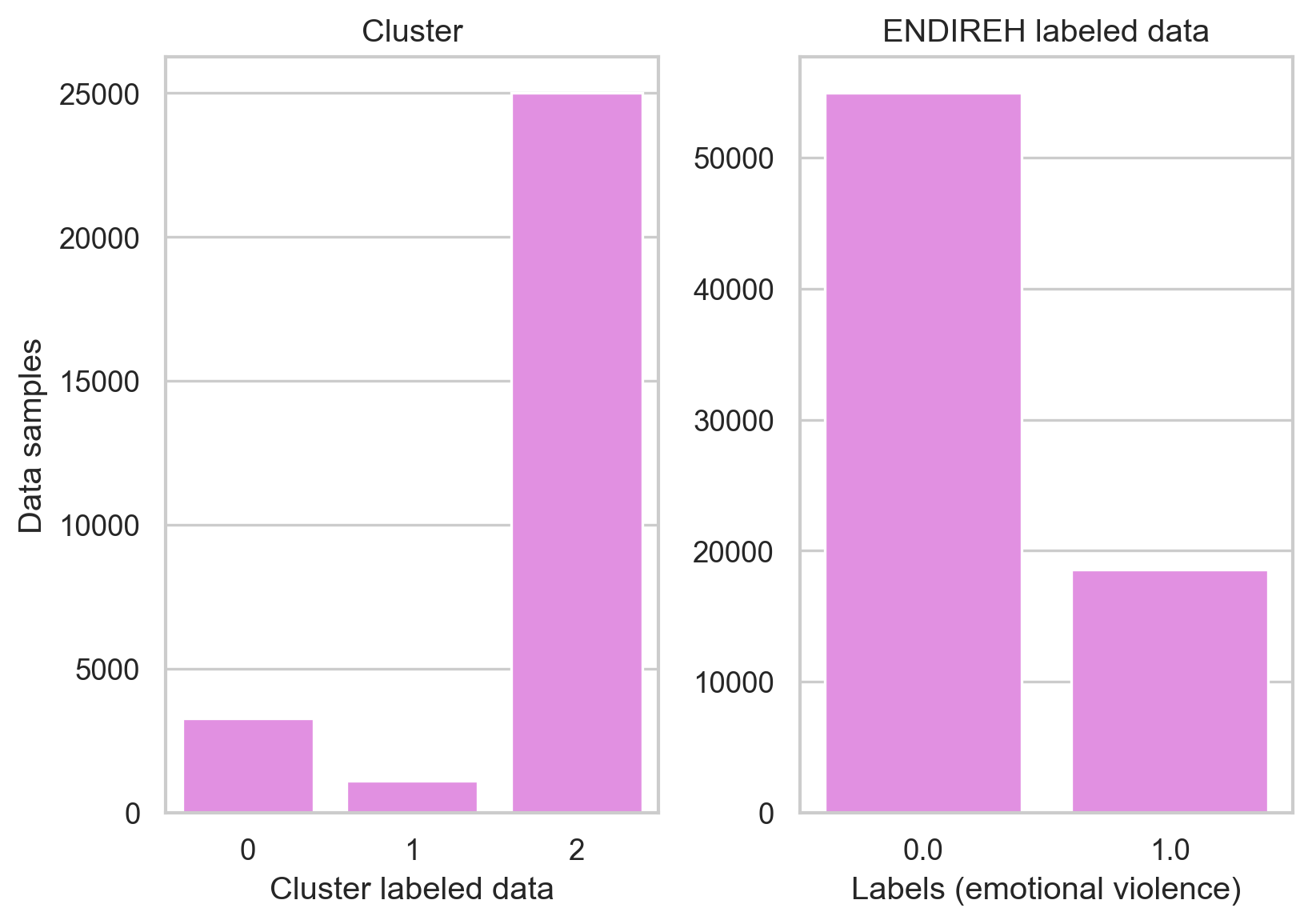
For this unsupervised learning task, we will focus on the ENDIREH survey results to understand the patterns and relations among answers on the survey about emotional violence.
We want to test if the clustering techniques are capable of separating our data into two clusters, the same way it is labeled for emotional violence and also perform an exploratory analysis of unaware relations. Since the data has more than 3 thousand columns, only an expert could deeply understand them; thus, analyzing our data to comprehend the relationship between questions without the “emotional violence” label is essential.
Model
Clustering algorithms partition sample data making similar data points grouped closer and different data points more distant from those in other groups.
Clustering is an unsupervised learning method. This method aims to find meaningful patterns, generative features, and groupings in sample data. The method’s flexibility makes it capable of performing different tasks depending on the user’s needs and data. For example, clusters’ applications are data reduction, outlier detection, or pattern search among influential data groups.
Clustering types
An essential difference while choosing clustering methods is whether the data clusters should be overlapped or separated. Therefore, this work focuses on two main types of clustering: Partitional and Hierarchical.
- Partitional clustering:
Selects sets of data into non-overlapping clusters. The most popular method is k-means which creates k number of groups, and each data point corresponds to one cluster.
The density-based approaches are a component of the partitional method. Density-based methods consider the groups with similarities as dense regions; the rest are lower dense regions of the space. These methods have good accuracy and can merge two clusters, for example, the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) model.
- Hierarchical clustering:
Performs nested clustering with a similar organization to a tree where new clusters are formed using the previously formed one. There are two subtypes of hierarchical clustering techniques, agglomerative or bottom-up and division or top-down.
The agglomerative type, contrary to k-means, does not assume the number of clusters, but one of the disadvantages of this technique is the high computational cost of the model. On the other hand, the Balanced Iterative Reducing Clustering and using Hierarchies (BIRCH) model requires the K number of clusters. Still, it has a low computational cost improving the clustering of sets with a high number of features.
K-means:
As previously mentioned, the k-means algorithm creates a k number of groups where each data point corresponds to one cluster. Firstly, the algorithm determines the best k-center points or “centroids.” Afterward, it will assign each data point to the closest centroid based on similarity or distance, as distance metric k-means minimizes squared Euclidean distance.
The model will continue to assign points to the nearest centroid and re-compute until it is converged. Although the method tends to fall into local minima, it can be solved by running several times.
DBSCAN:
As mentioned, this algorithm considers groups with similarities as dense regions and the lower dense regions of the space. One of its main advantages is not defining the number of clusters before running.
The algorithm defines the similarities as how “reachable” a point is from another. The densities are determined by the number of “neighbors” or close points a sample has; this method also measures similarity through a distance metric. Outliers are detected as points that are not closer to others in low-density regions to finally exclude them, which can be helpful for specific tasks.
Agglomerative:
The agglomerative or bottom-up technique obtains its name from how it clusters the data since each object is initially considered a “leaf.” The algorithm finds the two most similar clusters at each iteration and combines them to create a giant cluster or branch. It will iterate until all the data points are part of just one single big cluster (root), which can be seen as the “beginning of the “tree.”
Visualizing the agglomerative technique helps to determine the “optimal” number of clusters.
BIRCH:
Its main advantage is its high accuracy with huge datasets, given its reduced memory usage. BIRCH attempts to minimize the memory by summarizing information in dense regions by creating compact representations or subclusters called Clustering Feature (CF) entries.
As K-means, Birch requires the K desired number of clusters to divide the data and does not accept categorical attributes given that the data points are represented by coordinates in a Euclidean space.
Hyper-parameter tuning:
The most critical parameter to be tuned for clustering is the number of groups we want to divide the data on; for models that require that parameter.
Techniques such as the elbow method and silhouette are implemented to do an exploratory analysis of the parameters and finally select the best one.
- elbow method
This method is used to find the best number of clusters for k-means. It looks for the model with the lowest inertia and the lowest number of clusters; however, as the number of clusters increases, the inertia decreases, and the other way around. The elbow method aims to find the exact value as the decrease in inertia begins to slow.
- Silhouette method
This method aims to understand the distance between the clusters generated. It is a visual technique that shows how close the points of a cluster are to their cluster’s neighbors. Through it, the distance of clusters can be visualized in a range from -1 to 1.
Implementation
This unsupervised learning task will focus on the ENDIREH survey results. Since the data has more than 3 thousand columns, only an expert could deeply understand them; thus, analyzing our data to comprehend the relationship between questions without the “emotional violence” label is essential.
In order to do so, we will start by performing a feature selection implementing the best resulting method from the past Random Forest tab. Since the best feature selection only drops a small number of columns, it should be sufficient for improving the model accuracy but still, show relationships among our data.
Code
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay, accuracy_scorefrom scipy.spatial.distance import cdistfrom sklearn.cluster import KMeansfrom statistics import modeimport pandas as pdimport numpy as npimport matplotlibimport matplotlib.pyplot as pltimport seaborn as snsimport scipy.cluster.hierarchy as schimport sklearn.cluster as clustersns.set_theme(style ="whitegrid")
C:\Users\valer\AppData\Local\Temp\ipykernel_3032\361463827.py:1: DtypeWarning: Columns (188) have mixed types. Specify dtype option on import or set low_memory=False.
df = pd.read_csv('data/endireh_ev.csv', encoding='latin1')
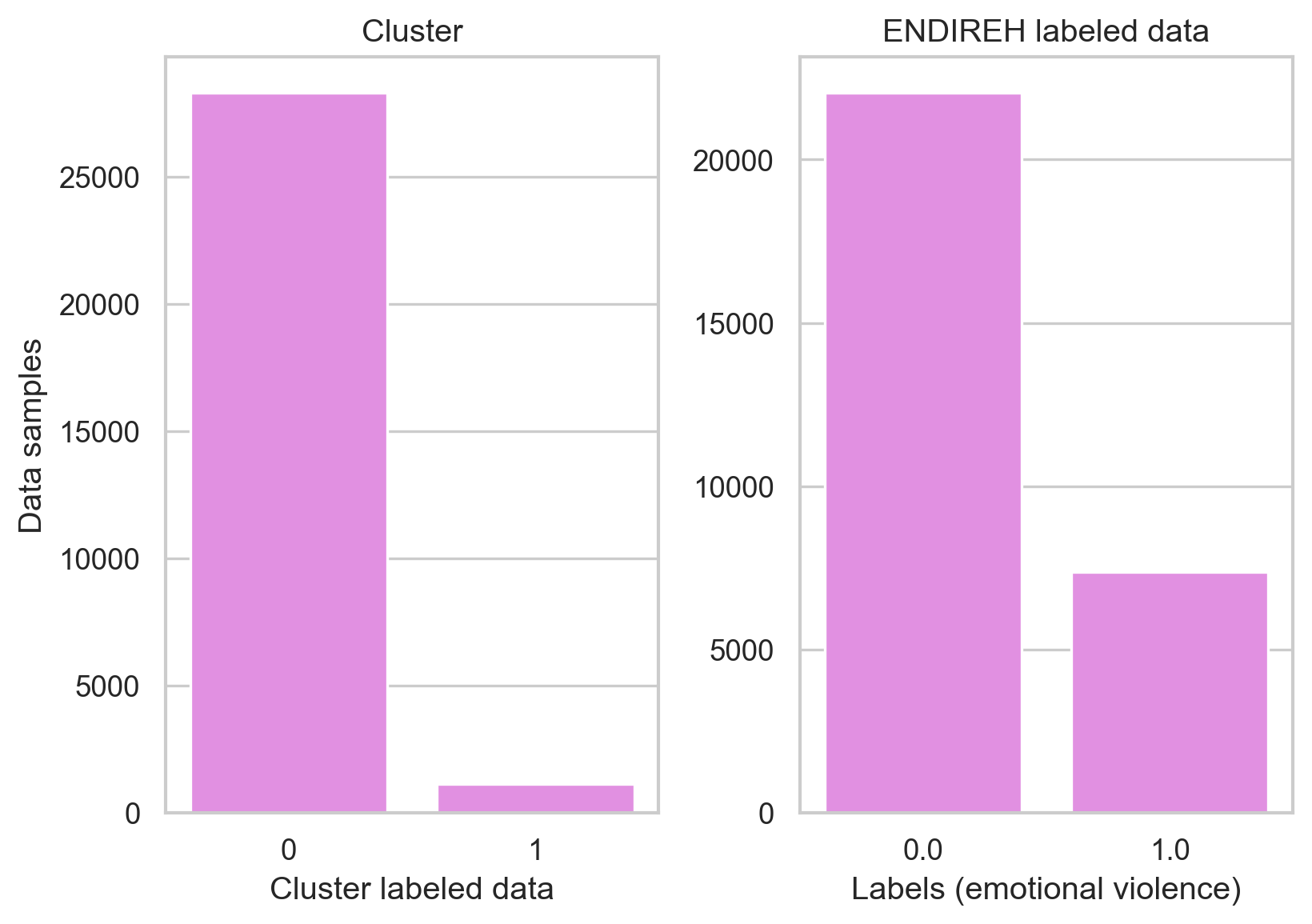
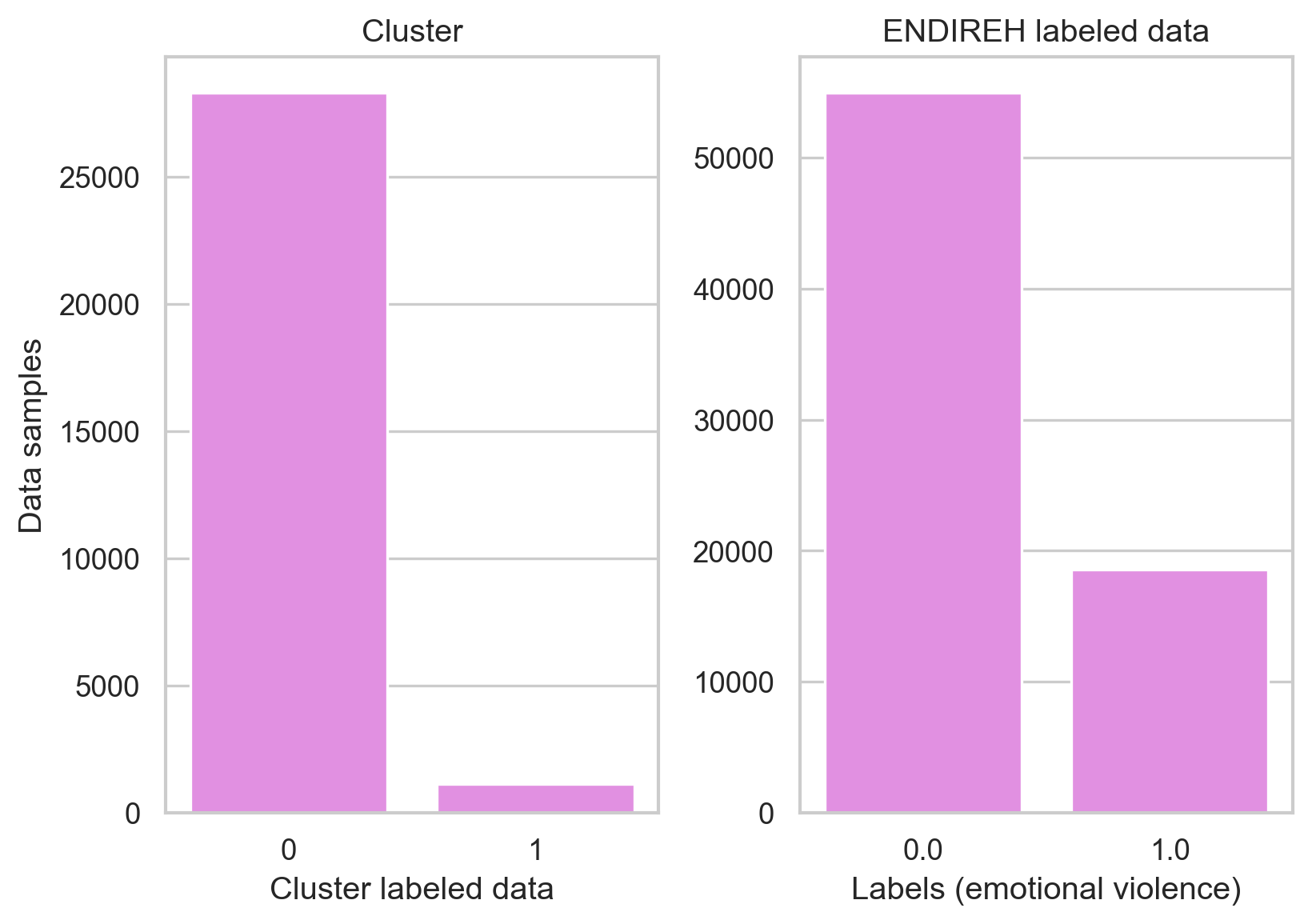
Since we have a binary label for emotional violence, the exploration will be performed to see if the clustering techniques are capable of separating the data as our label does by using a k equals to two.
K-means was capable of clustering the data on a similar balance as the original label, our data set is not balanced which can affect the performance of other models but it is important to see how this unbalanced behavior is replicated by the model. Although we cannot assume the clustering was divided by the “emotional violence” metric we have, there might be a relation that can be useful to predict emotional violence.
We will compare the samples with our label and the cluster obtained label through a confusion matrix
The results of the confusion matrix show how the model had issues with the data point that should have been labeled as “no emotional violence” and were labeled as “emotional violence”
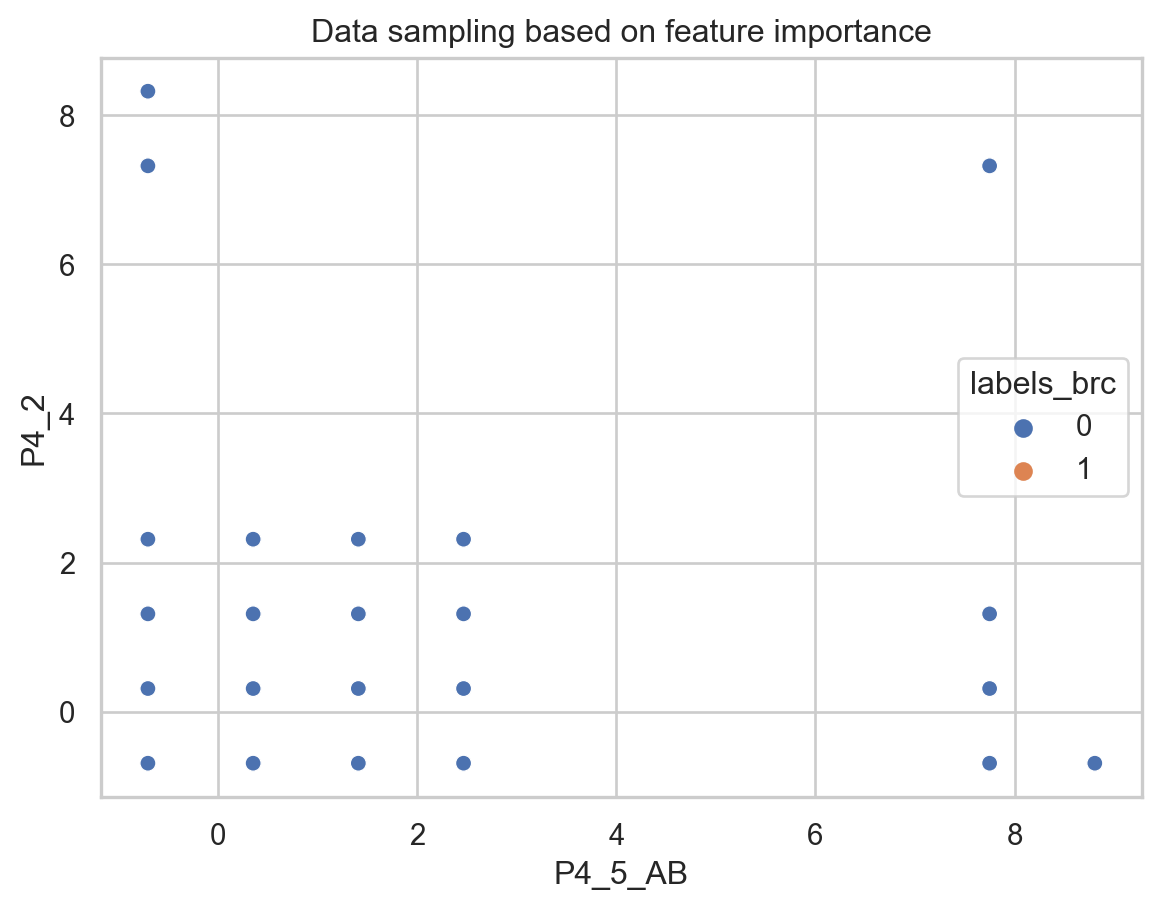
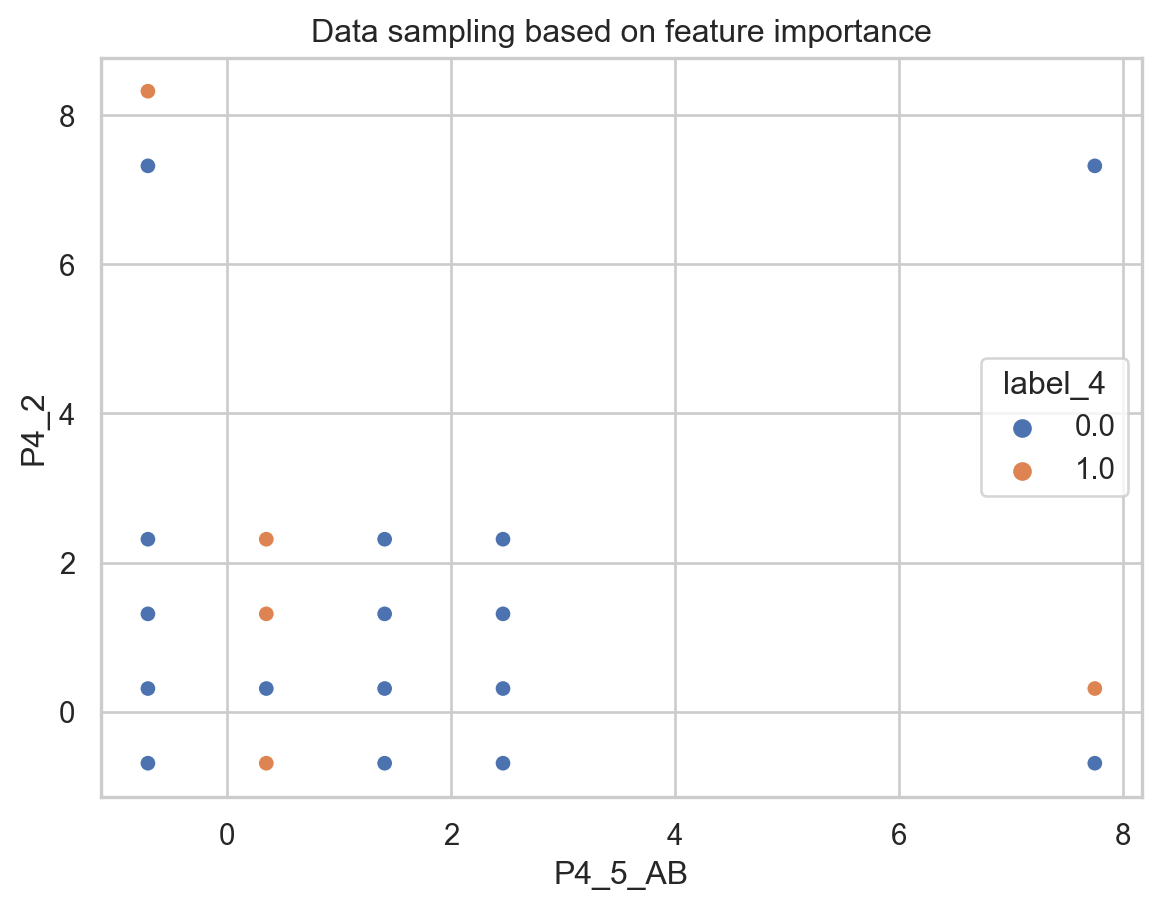
Finally, to compare the results, we will use the most critical features defined in the Decision Trees tab, which are “P4_2” corresponding to: “How frequently does your couple (who doesn’t live with you) visits you?” and “P4_5_AB”: “Economic income range of your partner.” These two features will be used to visualize how our data points are sampled when labeled as emotional violence or not.
sns.scatterplot(x="P4_5_AB",y="P4_2", hue ="cluster",data=predictions_cluster,palette="deep").set(title='Data sampling based on feature importance')
[Text(0.5, 1.0, 'Data sampling based on feature importance')]
Code
sns.scatterplot(x="P4_5_AB",y="P4_2", hue ="endireh",data=predictions_cluster,palette="deep").set(title='Data sampling based on feature importance')
[Text(0.5, 1.0, 'Data sampling based on feature importance')]
It is interesting to see how both behave the same. In this case we don’t care about the value of the label from the clustering assignment since it doesn’t have a representation, but we rather care about how the data was sampled, which is similar for the original labels and the clusters.
hyperparameter tuning
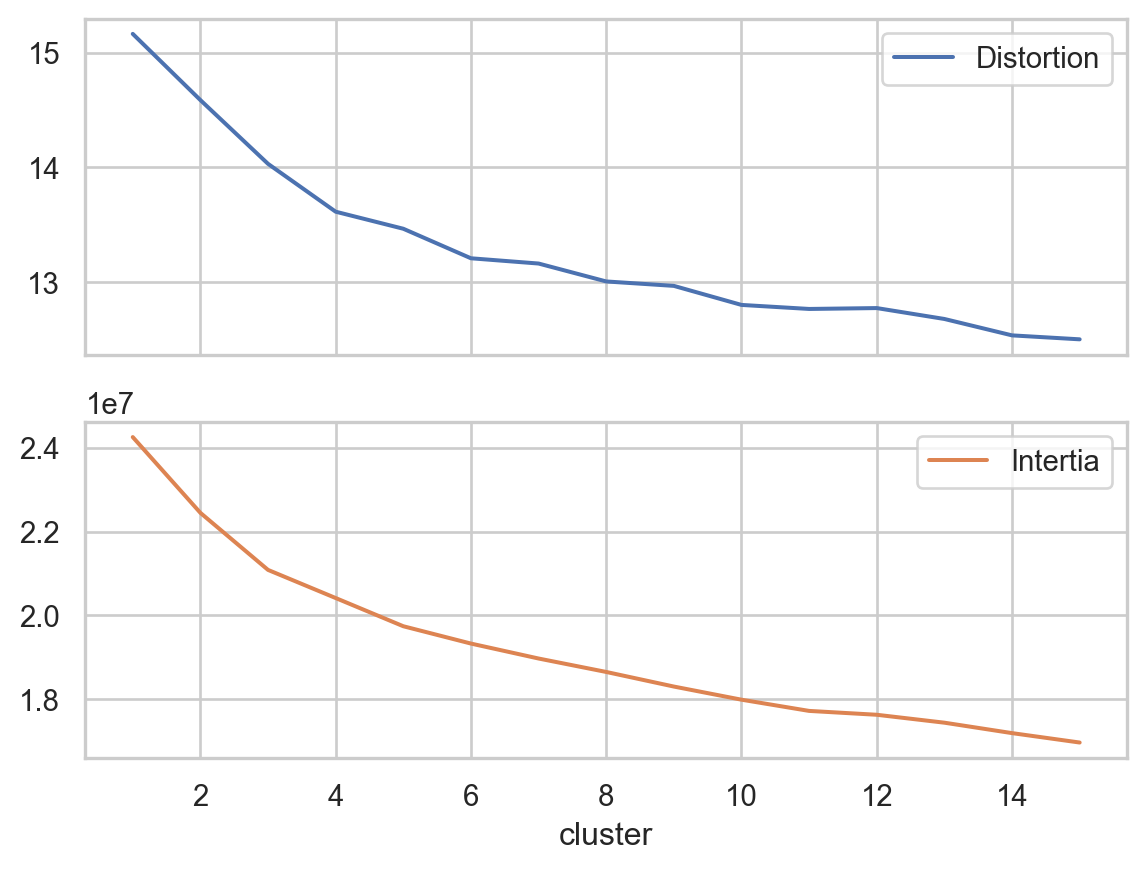
for k means clustering we will use the elbow method to find the optimal number of clusters. we will use the inertia_ attribute to find the sum of squared distances of samples to their closest cluster center. we will use the range of 1 to 15 clusters
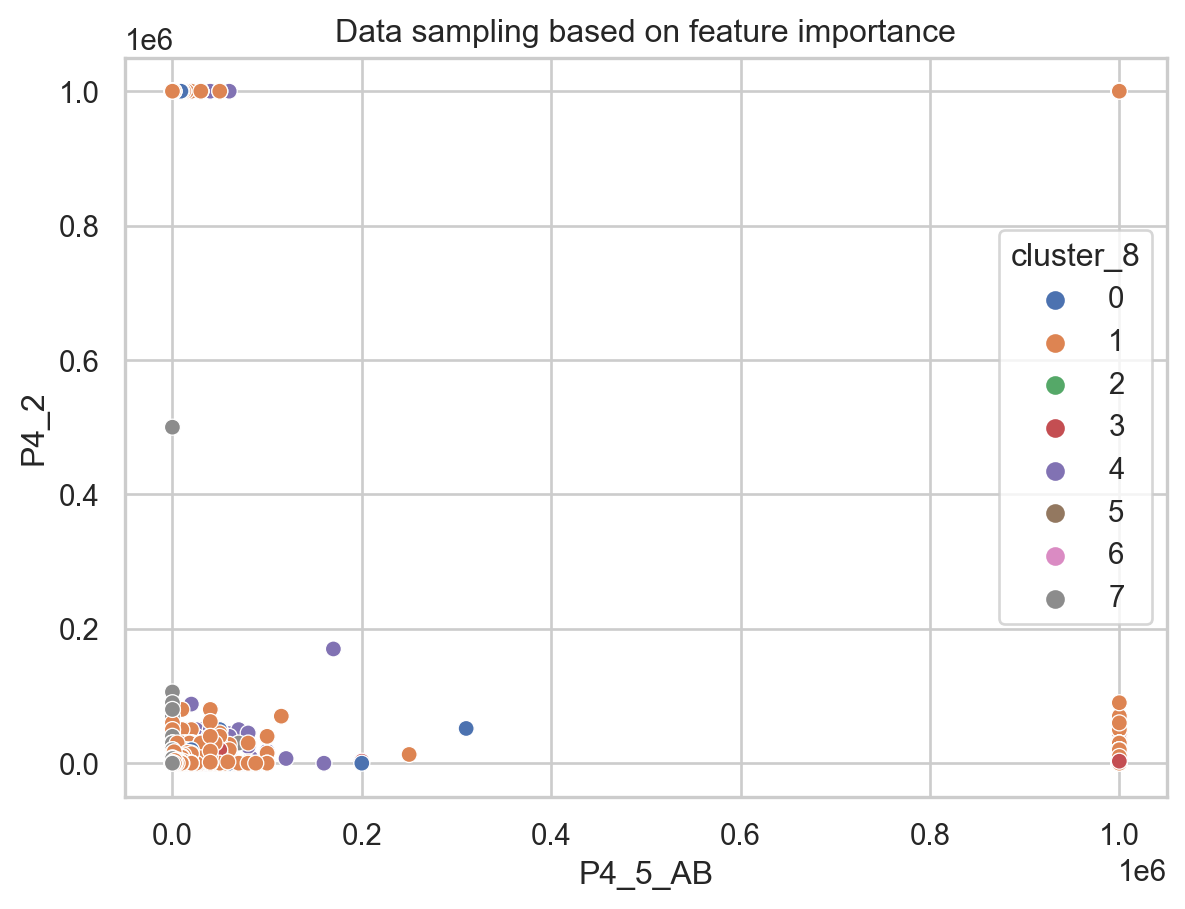
sns.scatterplot(x="P4_5_AB",y="P4_2", hue ="cluster_8",data=predictions_cluster,palette="deep").set(title='Data sampling based on feature importance')
[Text(0.5, 1.0, 'Data sampling based on feature importance')]
There might be a different pattern different to what we are looking for, which is emotional violence. This doesn’t mean there is no clustering among two groups but rather the similarity is closer in those 8 groups than having two big groups.
Through this we can assume there are patterns among the women who has suffered emotional violence.
DBSCAN clustering
For this method we will also experiment with 2 clusters to compare the values against k-means
Code
from sklearn.cluster import DBSCANpredictions = DBSCAN(eps=2.5, min_samples=2).fit(df_scaled)predictions_cluster["DBSCAN"] = predictions.labels_print(predictions_cluster.head(3))
From the repetition of the labels we can see there is one big cluster for 72559 points while the rest of them are labeled different from each other. We could assume this as the rest of the points being outliers or, since we know our data is unbalanced we can assume those points as our negative label.
We will try to replicate the experiment with a bigger number of min samples to see if those points can be grouped together
Even after reducing the dataset by 60% the agglomerative reproduced the behavior of having a small number of data on one class. Although the behavior is similar, agglomerative had a really small number of datapoints on one class which can be related to outliers rather to the separation of the target we are looking for.
Code
"""Commenting due to the high usage of memory to re-compute the dendrogramZ = linkage(X_train_4, method="ward")dend = dendrogram(Z)"""
'\nCommenting due to the high usage of memory to re-compute the dendrogram\n\nZ = linkage(X_train_4, method="ward")\ndend = dendrogram(Z)\n\n'
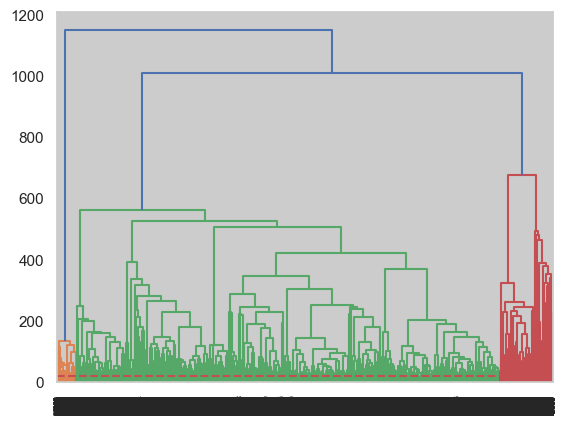
dendrogram
Even though the model did not performed as good as K- means by comparing the “emotional violence” labels, by looking at the dendrogram generated with the agglomerative technique we can visualize the huge number of features, thus truncating is important. On the other hand, the model not performing so good or providing a huge cluster can be seen on this visualization, the red separation might be the class with less data points while the big class has a huge number of clusters inside.
The meanshift technique will be used to continue the exploration of the optimal number of clusters
The result of this technique shows a huge number of clusters in our data. Two assumptions can be made from the number of estimated clusters, which is half the number of data points we have; our data is so sparsed we only have couples of data points or assume the same behavior seen from DBSCAN and the agglomerative technique, where we have a big data set with smaller outliers around it.
BIRCH
Although the birch method should reduce memory usage, the dataset is too complex to perform on a low-memory laptop thus we will also use the reduced train for this exploration
Code
from sklearn.cluster import Birchbrc = Birch(n_clusters =2).fit(X_train_4)labels_brc = brc.predict(X_train_4)labels_brc
sns.scatterplot(x="P4_5_AB",y="P4_2", hue ="labels_brc",data=df_4,palette="deep").set(title='Data sampling based on feature importance')
[Text(0.5, 1.0, 'Data sampling based on feature importance')]
Code
sns.scatterplot(x="P4_5_AB",y="P4_2", hue ="label_4",data=df_4,palette="deep").set(title='Data sampling based on feature importance')
[Text(0.5, 1.0, 'Data sampling based on feature importance')]
Although the model resulted similar to past approaches, from the scatterplot with reduced data we can see the behavior is similar to past ones, most data points with “no emotional violence” are the ones who have a lower value in P4_5_AB and P4_2
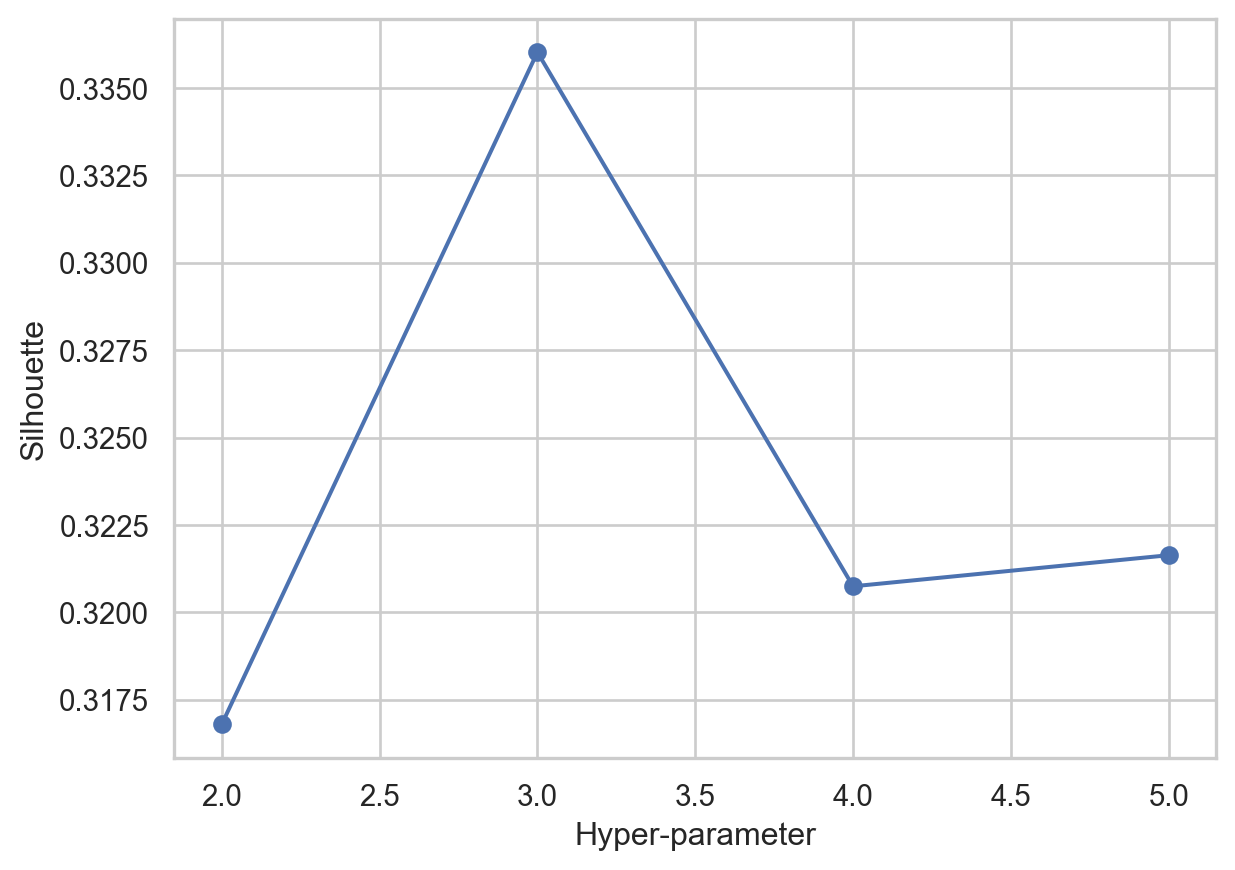
Finally we will perform the silhouette method to find the besy hyperparameters for BIRCH, to compare the results with a bigger number of clusters
C:\Users\valer\anaconda3\envs\ANLY501\lib\site-packages\sklearn\utils\validation.py:1858: FutureWarning: Feature names only support names that are all strings. Got feature names with dtypes: ['int', 'str']. An error will be raised in 1.2.
warnings.warn(
C:\Users\valer\anaconda3\envs\ANLY501\lib\site-packages\sklearn\utils\validation.py:1858: FutureWarning: Feature names only support names that are all strings. Got feature names with dtypes: ['int', 'str']. An error will be raised in 1.2.
warnings.warn(
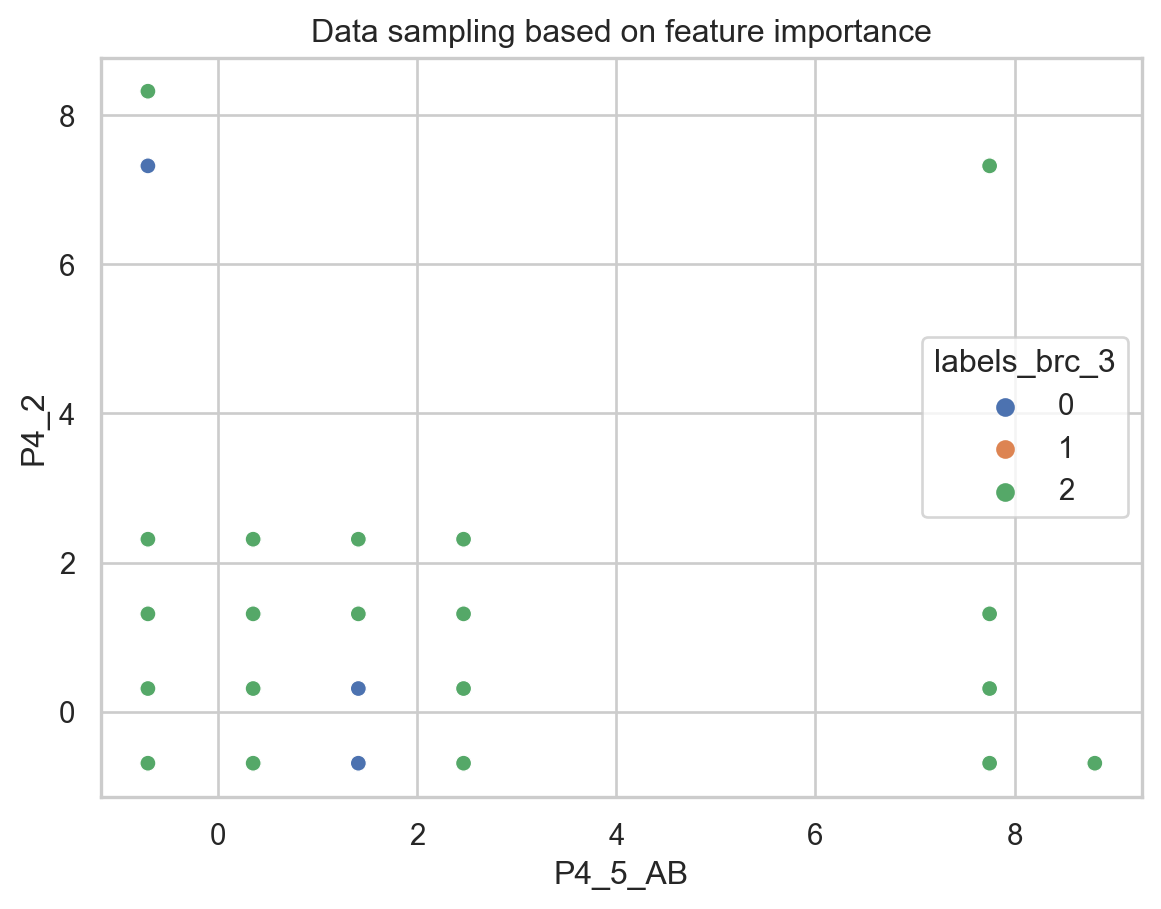
df_4["labels_brc_3"] = labels_brcsns.scatterplot(x="P4_5_AB",y="P4_2", hue ="labels_brc_3",data=df_4,palette="deep").set(title='Data sampling based on feature importance')
[Text(0.5, 1.0, 'Data sampling based on feature importance')]
Results
Results
K-means performed quickly in terms of computational time, and although it followed the same unbalanced labeling as the original, it had many mistaken data points. From the confusion matrix, we can assume the point errors were mostly on false negative values. From the scatterplot of the two most essential features, we can visualize how the true positives increase while the range of those answers increases as well. That behavior was replicated with the K-means model labeling.
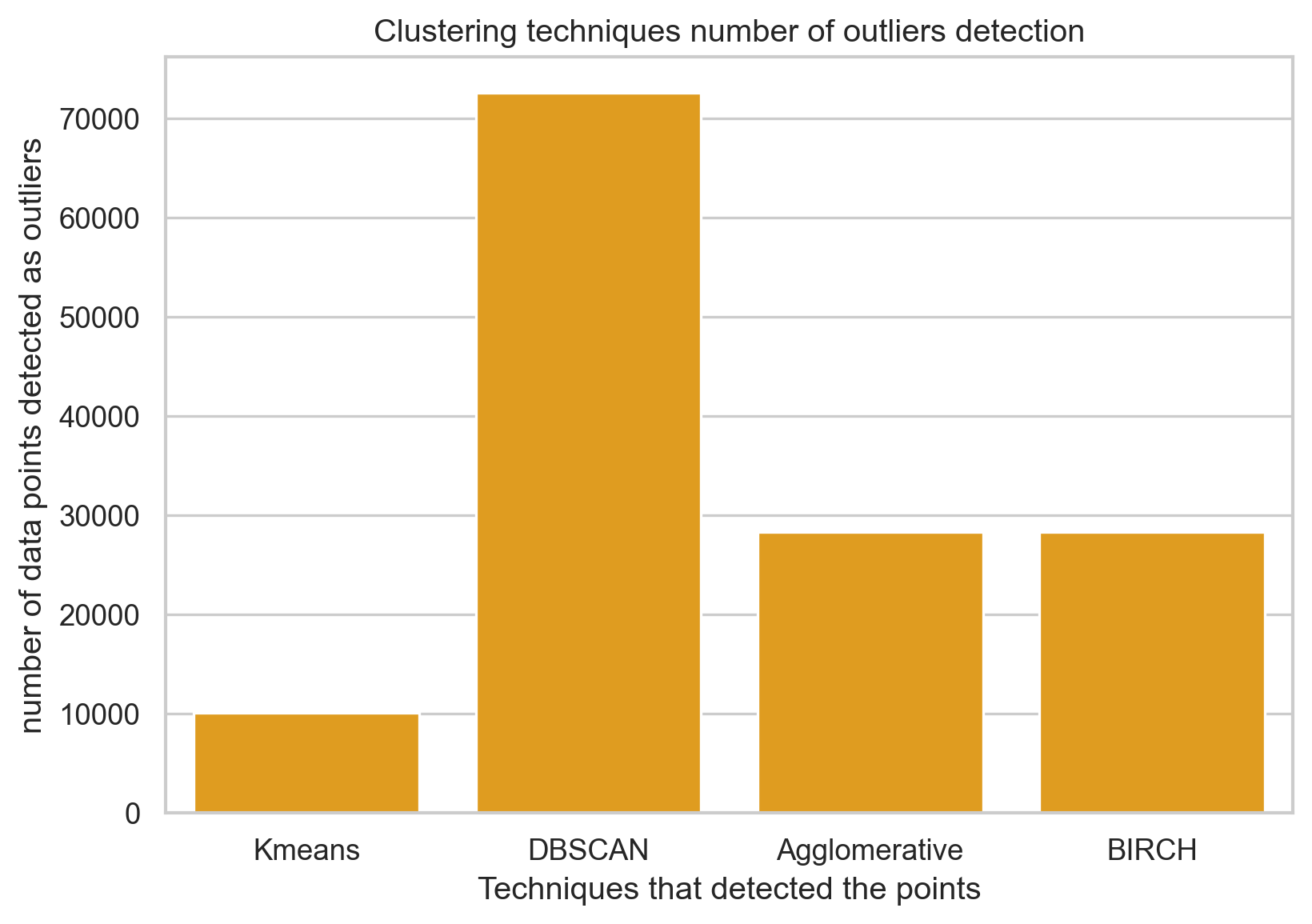
Although the elbow technique does not help in terms of clustering by “emotional” violence or not, the result was significant in terms of exploration, returning the best value of 8. The results for DBSCAN were not as straightforward to compute and understand; the model could not differentiate between emotional violence or not but detected the outliers since it labeled together 72559 points leaving around 500 points clustered by pairs.
The agglomerative technique performed similarly to DBSCAN, returning a small number of labels for one class, leading to an outlier detection rather than separating the two classes. A dendrogram was generated with the agglomerative technique, which helped understand the relations among clusters. It shows how two groups of outliers branch out to smaller groups while a big group contains a more considerable number of clusters; we can assume the big group is the “emotional violence” data points. The mean-shift technique was implemented to support this method’s results, returning almost 30,000 clusters as a result (half of the total data points).
Although the BIRCH method aims to reduce memory usage, it needed to allocate more to run the whole dataset. After reducing the samples, the method performed similarly to past ones, returning a minimal number of samples for one category after clustering into two groups. Finally, we used the silhouette method to find the optimal number of clusters within 1 and 5 (given the memory usage of the algorithm). The result was 3 clusters. How the data was sampled with 3 clusters also demonstrates two sub-clusters among the outliers or “non-violent” cases.
Code
techniques = ["Kmeans","DBSCAN","Agglomerative","BIRCH"]f, ax = plt.subplots(dpi=120)sns.barplot(x=techniques, y=outliers, color ='orange',)ax.set_ylabel("number of data points detected as outliers", fontsize=12)ax.set_xlabel("Techniques that detected the points", fontsize=12)ax.set_title("Clustering techniques number of outliers detection", fontsize=12)f.tight_layout()
Conclusion
Among the implemented clustering techniques, the results were quite similar between all of them. Most of the techniques classified the “non-violent” examples as outliers and could find around 5 to 8 clusters inside the “violent” data points.
In terms of errors, most models separated false negatives incorrectly. In real-life applications for social problems having a model that predicts false negatives might be a better scenario than a model predicting false negatives.
Even though we were looking for the models’ results to separate the data by “emotional violence” and “non-emotional violence,” the elbow method in k-means and the silhouette method in BIRCH explore different patterns among data. From it, we can deeply explore the cases where emotional violence occurs, moving aside the non-violent cases to understand the social problem. One gave, as a result, the optimal number of clusters as eight and the other three.
Clustering served to do an exploratory analysis of our ENDIREH Data. These techniques helped us to realize how unbalanced our set is and how important it would be to drop the outliers and “non-emotional violence” data points to find more meaningful relations.
In future steps, the data will be reduced in terms of redundant features to have a smaller set. Outliers will also be removed to re-compute the past methods and understand the clusters that were pointed out by the model’s results.