Through this method we are also looking into different techniques to improve our data modelling and finally, improving the prediction.
Some of the techniques to improve data modelling include dropping columns with single and unnecessary values. Secondly Standardize all of our columns given some of their values have wide ranges and finally, we will also be looking at the feature selection technique. Feature selection provides multiple advantages such as removing irrelevant and redundant features that have no relation with the target variable and are unrelated to the task the model is designed to solve. Doing this helps to solve dimensionality problems related to a large training time and difficult in interpreting the model’s results.
Besides reducing the number of features that our model will receive we can “tune” our model through hyperparameters. Tuning means finding the optimal hyperparameter values for the algorithm to maximize the model’s performance with the data it received and finally improve it’s prediction results.
Going Further into the implementation, for decision trees we decided to utilize different data. We extracted columns from the data we have already obtained and cleaned. This columns are answers from the ENDIREH survey described before, the answers we extracted describe the characteristics of each mexican women’s past and actual relationships and characteristics about their couple. We want to use those characteristics to predict if a woman has experienced emotional violence in her relationship. Finally we have 425 columns each representing one question or characteristic.
Model
Decision Trees are a non-parametric supervised learning classification models which can learn from data to approximate a value based on a set of if-then-else decision rules, that will end up looking like a tree. The decision criteria are more complex and the model is more accurate the deeper the tree is.
Decision Trees are simple to understand and to visually interpret. We can see them as a white box model where if a feature is important to the model, then the condition is easily observed by a boolean decision.
On the other hand Decision Trees can create over-complex trees leading to overfitting. To avoid this issue, mechanisms like pruning, minimum number of samples required at a leaf node, or maximum depth of the tree are required.
Code
from sklearn.preprocessing import StandardScalerimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import ConfusionMatrixDisplay, accuracy_score, recall_scorefrom sklearn.metrics import confusion_matriximport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport matplotlib.stylematplotlib.style.use('seaborn-pastel')df = pd.read_csv('data/endireh_ev.csv', encoding='latin1')print(df.shape)df.loc[:, df.apply(pd.Series.nunique) !=1]df.replace([np.inf, -np.inf], np.nan).dropna(axis=1)print(df.shape)df.head(5)
C:\Users\valer\AppData\Local\Temp\ipykernel_7968\1224648129.py:12: DtypeWarning: Columns (188) have mixed types. Specify dtype option on import or set low_memory=False.
df = pd.read_csv('data/endireh_ev.csv', encoding='latin1')
(73500, 354)
(73500, 354)
P12_1
P12_2
P12_3
P12_4
P12_5
P12_6
P12_7
P12_8
P12_9
P12_10
...
P4_13_4
P4_13_5
P4_13_6
P4_13_7
FAC_VIV_y.1
FAC_MUJ_y.1
ESTRATO_y.1
UPM_DIS_y.1
EST_DIS_y.1
label
0
2
1
2
3
1
3
3
8.0
8.0
3.0
...
1.0
NaN
NaN
NaN
113
113
4
1
3
1.0
1
1
1
3
3
3
1
3
1.0
2.0
4.0
...
5.0
NaN
NaN
NaN
113
113
4
1
3
0.0
2
2
1
1
3
3
3
1
3.0
8.0
1.0
...
2.0
NaN
NaN
NaN
78
155
2
2
1
0.0
3
1
1
3
1
1
1
1
1.0
2.0
3.0
...
1.0
NaN
NaN
NaN
78
78
2
2
1
0.0
4
1
1
4
3
3
3
3
8.0
8.0
3.0
...
5.0
NaN
NaN
NaN
78
78
2
2
1
0.0
5 rows × 354 columns
To obtain the label we looked at two questions on the survey which described different situations were the woman has experienced psychological violence and she should select the date range when those happened or if those did not occur. We transformed those ranges into a binomial decision 1 if the woman has suffered emotional violence on her present or past relationships and 0 if she has not.
While cleaning we realized the classes were not balanced, around 70% of the data were labeled as 0 or “no emotional violence” thus we decided to randomly select a small number of data points that were labeled as 0. Finally, the data is almost balanced:
Code
#check balance of the classesdef check_balance(df):print(df.label.value_counts())check_balance(df)
0.0 54940
1.0 18560
Name: label, dtype: int64
Since we have a big number of features we want to normalize them before splitting our data for training the model.
from sklearn import treemodel = tree.DecisionTreeClassifier()
Code
model.fit(X_train, y_train)
DecisionTreeClassifier()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
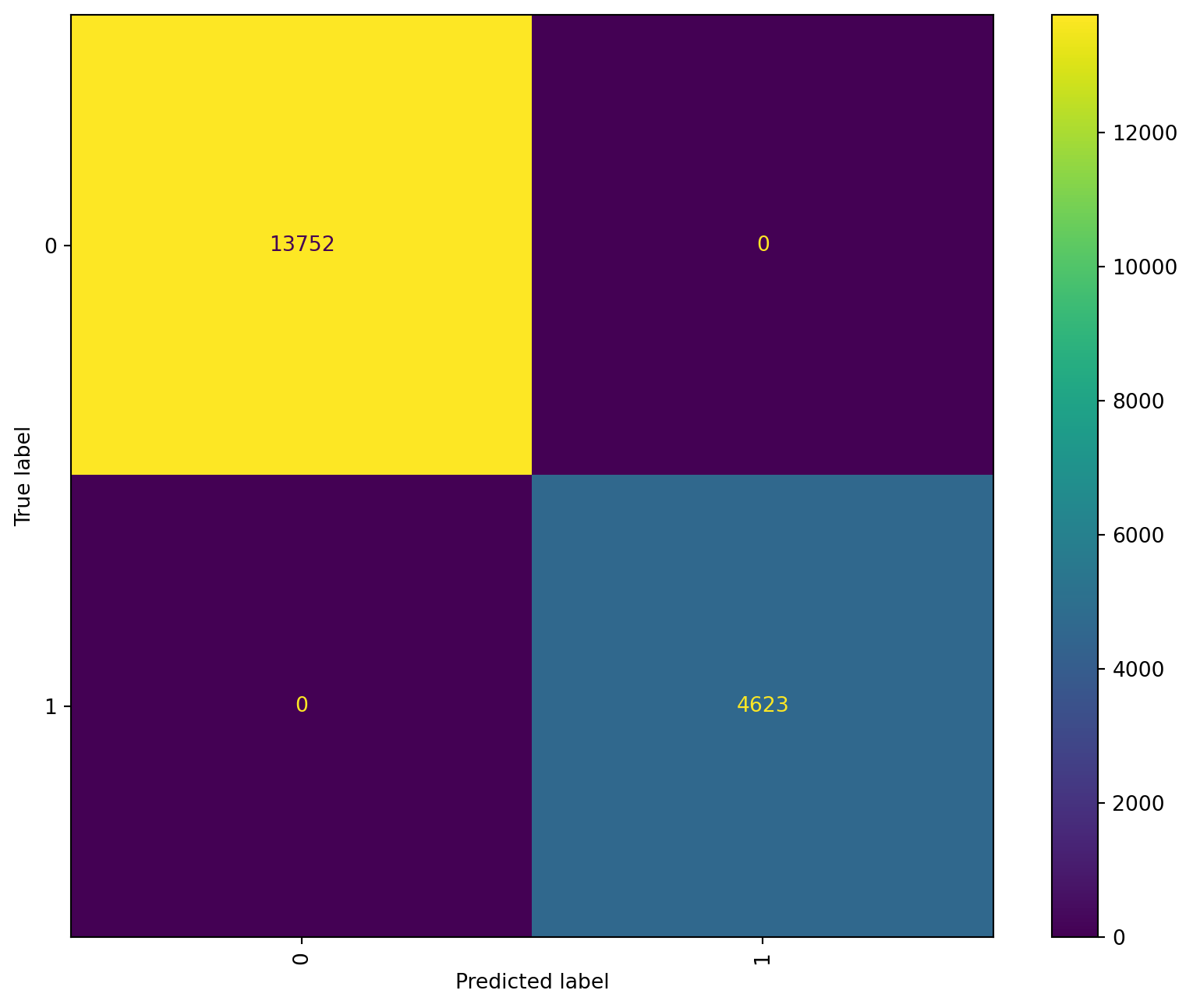
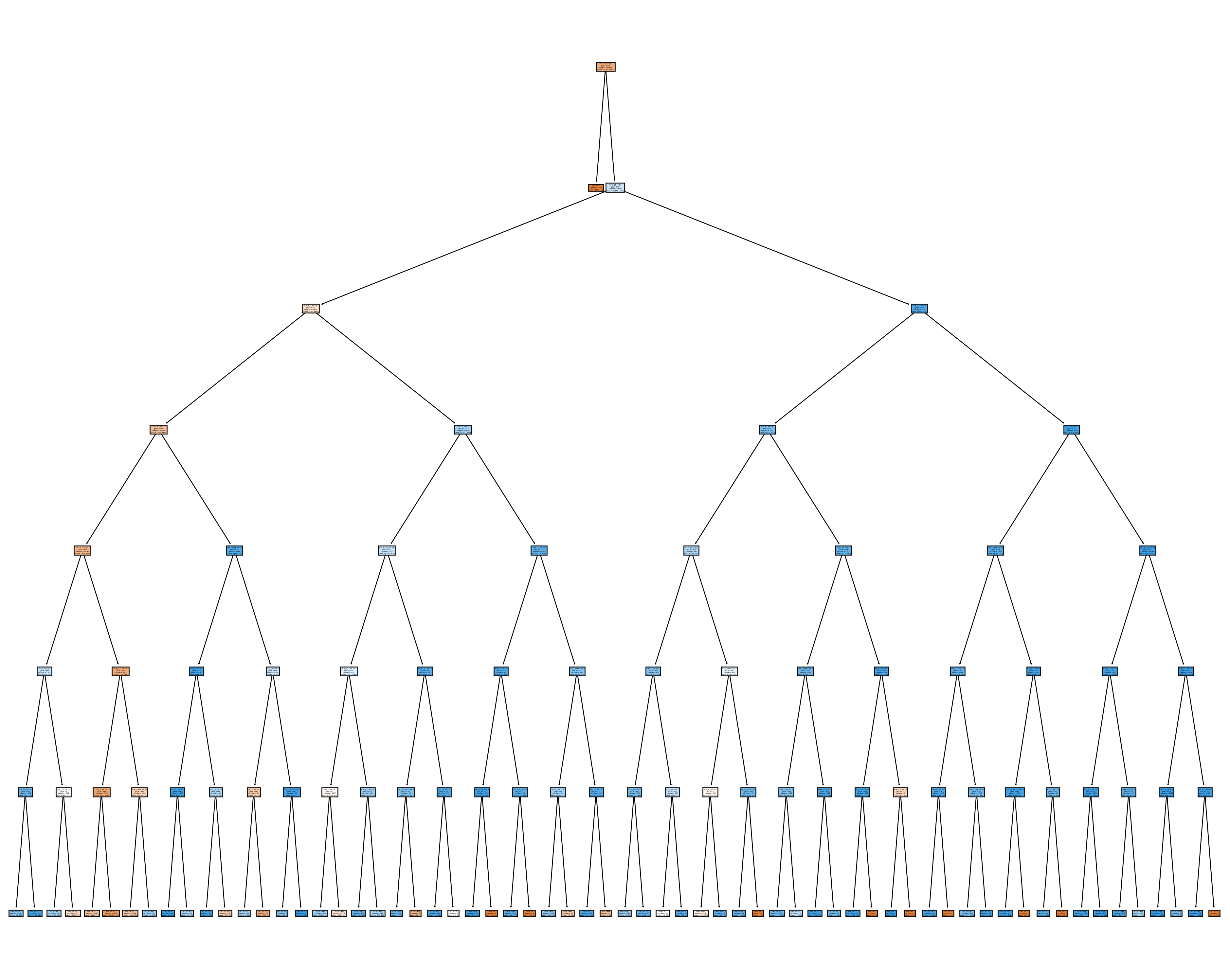
After looking at the results we can see the classifier perfectly classified all test values, we will plot the decision tree to understand this behavior
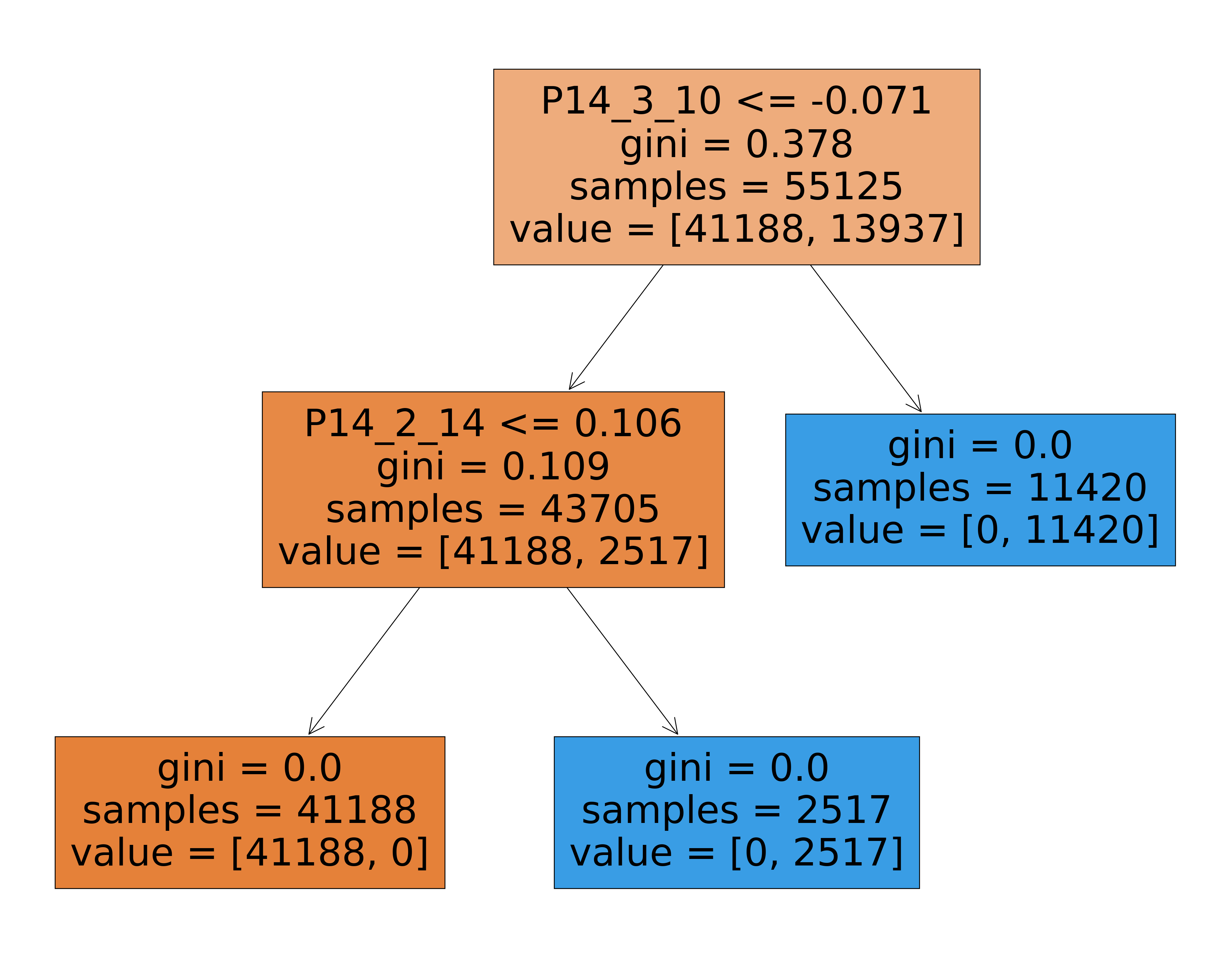
By looking at it we can understand this is a mistake. Feature P_14_2_10 is redundant to the feature we used as label P_14_1_10. Both question described similar emotional violence experiences, so if a women answered yes to P_14_2_10 (most important feature) they answered yes to our label (P_14_1_10). We can see this as a cleaning mistake so we will drop this column and re train.
After dropping the column we can see our model is still small, the reason behind it is that all features starting with P14_ and ending with 14 and 10 describe emotional violence and the scenarios were it happened, thus the model is picking those up as the most important features to predict emotional violence.
Since we want to understand which are the most important characteristics to predict emotional violence, without having information regarding emotional violence, we decided to drop all columns related to it.
After having a model which was not trained with “biased” data we can see a bigger tree. The accuracy was better than expected, but the tree might be overfitted given how deep the three looks like, we will experiment on hyperparameter tuning to improve the model results.
Code
#Experimenting with threshold around .001 and .1 best .07selector = VarianceThreshold(threshold=.07)X_vr = selector.fit_transform(X)print(X.shape)print(X_vr.shape)X_train, X_test, y_train, y_test = train_test_split(X_vr,y)model.fit(X_train, y_train)y_pred = model.predict(X_test)print_report(y_test, y_pred)#plot_tree(model,X_train,y_train)
Experimenting with Variance Threshold parameter increased the model accuracy
Code
from sklearn.feature_selection import SelectKBest, chi2print(X.shape)#Experimenting with k number of feature selection best 350selector = SelectKBest(chi2, k=320)X_chi= selector.fit_transform(X, df["label"])k_f_names = X.iloc[:,selector.get_support(indices=True)]X_train, X_test, y_train, y_test = train_test_split(X_chi,y)model.fit(X_train, y_train)y_pred = model.predict(X_test)print_report(y_test, y_pred)#plot_tree(model,X_train,y_train,k_f_names.columns)
Experimenting with Select K best feature importance k values, the best k value is 320 and the accuracy increased in comparison to using variance threshold
Code
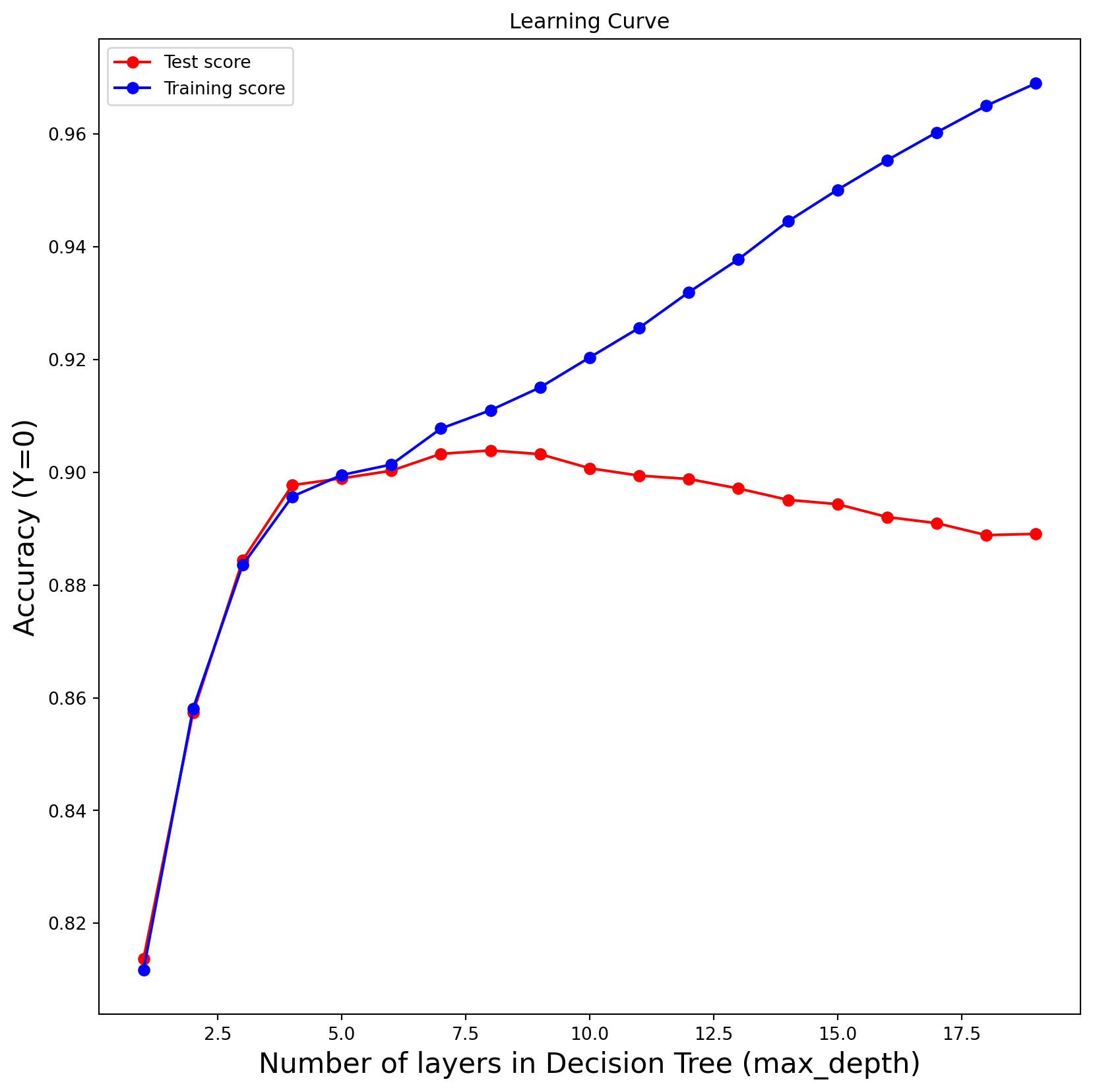
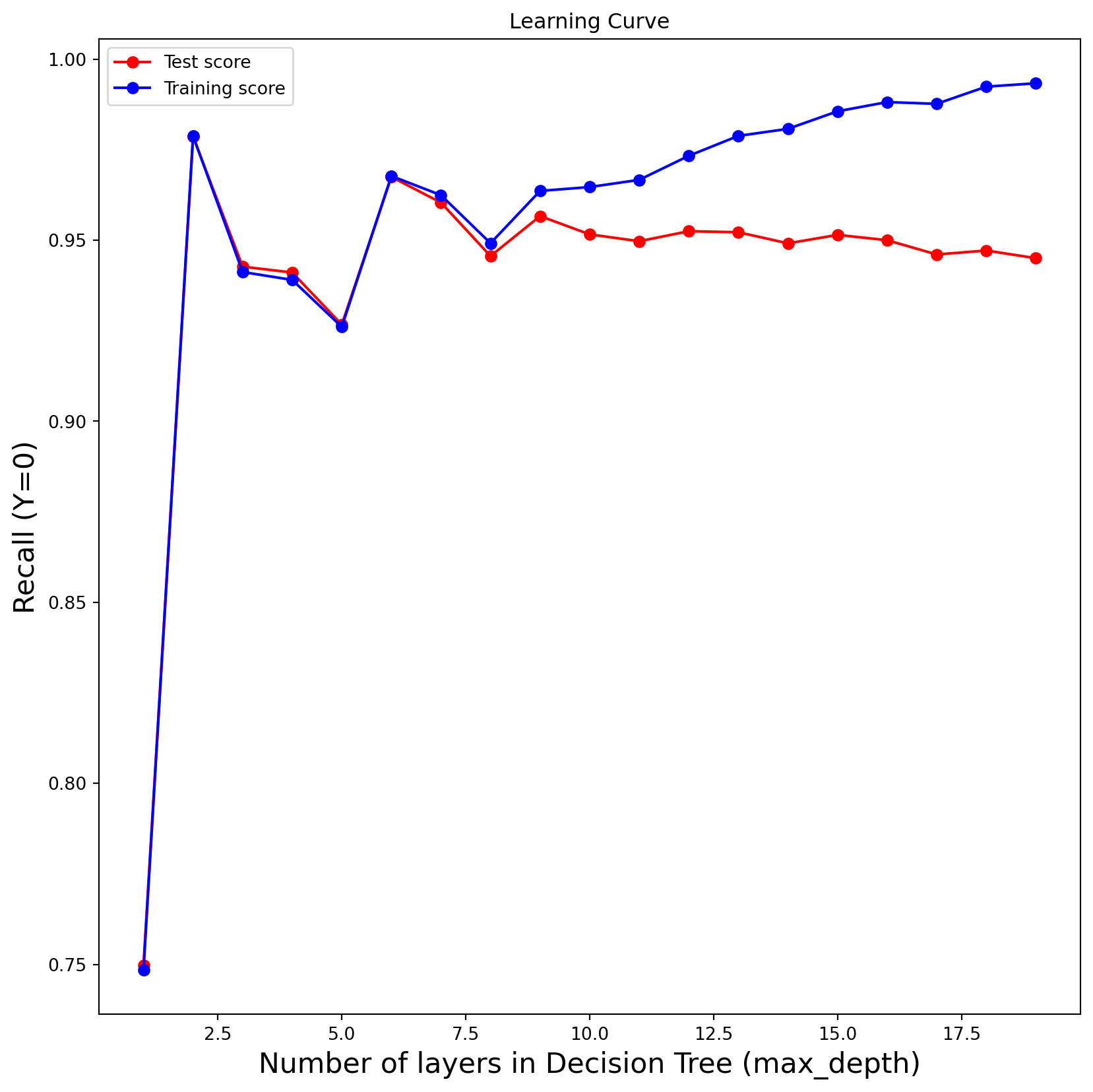
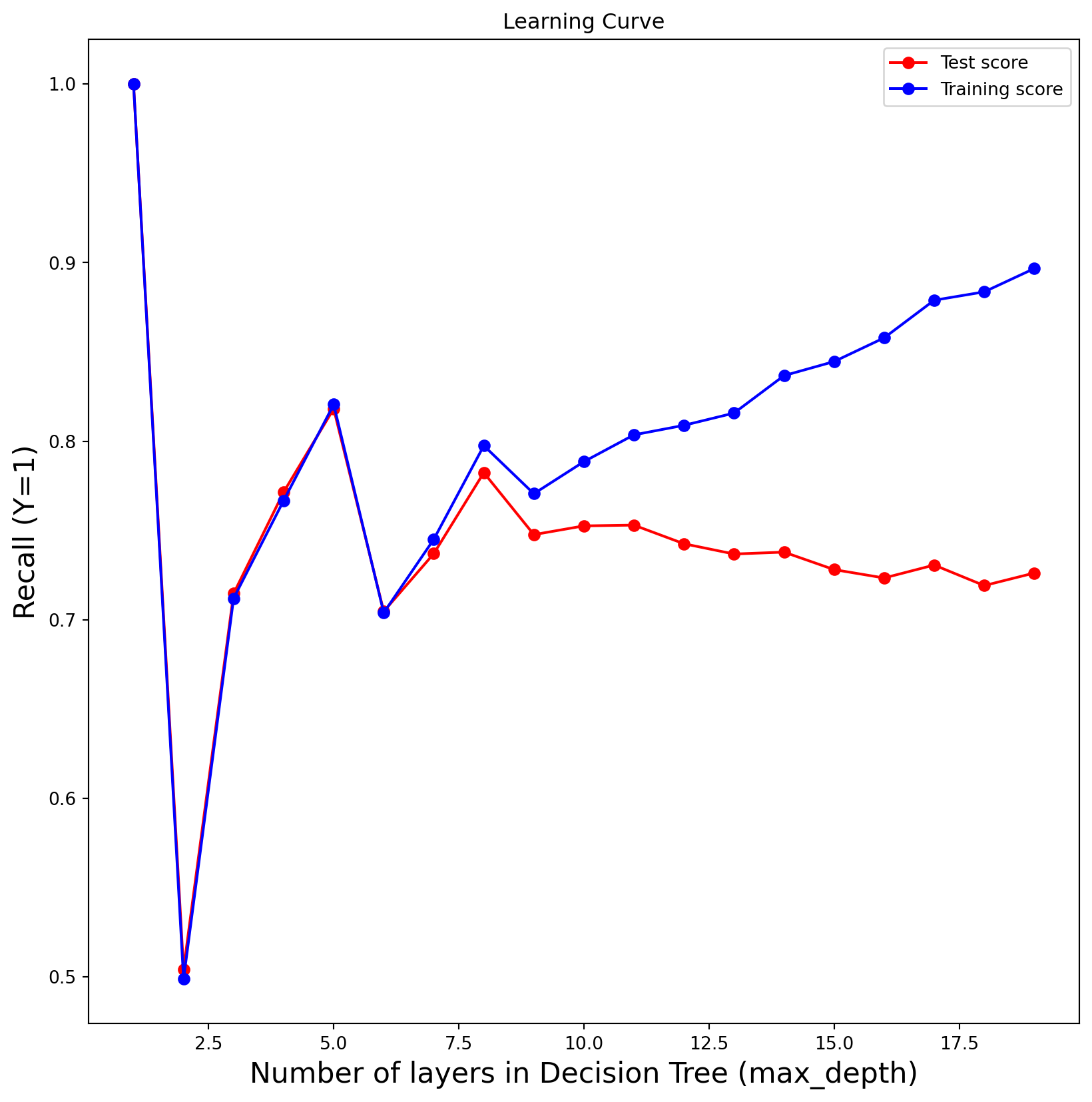
test_results = []train_results = []for num_layer inrange(1,20): model = tree.DecisionTreeClassifier(max_depth=num_layer) model = model.fit(X_train,y_train) yp_train=model.predict(X_train) yp_test=model.predict(X_test) test_results.append([num_layer,accuracy_score(y_test, yp_test),recall_score(y_test, yp_test,pos_label=0),recall_score(y_test, yp_test,pos_label=1)]) train_results.append([num_layer,accuracy_score(y_train, yp_train),recall_score(y_train, yp_train,pos_label=0),recall_score(y_train, yp_train,pos_label=1)])labels = ["","Accuracy (Y=0)","Recall (Y=0)","Recall (Y=1)"]for i inrange(1,4): plt.subplots(1, figsize=(10, 10)) plt.plot(range(1,20), [x[i] for x in test_results], label="Test score", color="red",marker="o") plt.plot(range(1,20), [x[i] for x in train_results], label="Training score", color="blue",marker="o") plt.title("Learning Curve") plt.xlabel("Number of layers in Decision Tree (max_depth)",fontsize=16), plt.ylabel( labels[i],fontsize=16), plt.legend(loc="best") plt.show()
Experimenting with the Number of layers in the Decision Tree hyperparameter (max depth) By looking at our plots we can see the model’s peak is around 5 and 7.5, closer to 7.5 thus we selected the best max_depth as 7
Code
model = tree.DecisionTreeClassifier(max_depth=7)model.fit(X_train, y_train)y_pred = model.predict(X_test)print_report(y_test, y_pred)
By looking at our metrics we can observe the impact of hyperparameter tuning in our model
Code
plot_tree(model,X_train,y_train,k_f_names.keys())
Code
#random classifierimport numpy as npimport randomfrom collections import Counterfrom sklearn.metrics import accuracy_scorefrom sklearn.metrics import precision_recall_fscore_supportdef random_classifier(y_data): ypred=[] max_label=np.max(y_data);#print(max_label)for i inrange(0,len(y_data)): ypred.append(int(np.floor((max_label+1)*np.random.uniform(0,1))))print("count of prediction:",Counter(ypred).values()) # counts the elements' frequencyprint("probability of prediction:",np.fromiter(Counter(ypred).values(),dtype=float)/len(y_data)) # counts the elements' frequencyprint("accuracy",accuracy_score(y_data, ypred))print("precision, recall, fscore,support",precision_recall_fscore_support(y_data,ypred))print("\nBINARY CLASS: ENDIREH data")random_classifier(y_train)
BINARY CLASS: ENDIREH data
count of prediction: dict_values([27545, 27580])
probability of prediction: [0.49968254 0.50031746]
accuracy 0.49844897959183676
precision, recall, fscore,support (array([0.74680928, 0.2497731 ]), array([0.499176 , 0.49628508]), array([0.59838471, 0.33230294]), array([41262, 13863], dtype=int64))
As a baseline comparison, we are implementing a random binary classifier trained with our data to compare it with the model we just built. Based on this results we can see that our model did better by more than 30% of accuracy
As a conclusion the “mistakes” on the data modelling (not dropping all columns related to emotional violence) made it easier to understand the logic behind decision trees. After removing those, we were able to see the impact of correct data modelling through manual cleaning, feature selection and hyperparameter tuning.
After dropping unnecessary columns we had almost 400 features, the Variance Threshold feature selection technique reduced them to 315 which improved the accuracy but did not performed as well as The K best feature selection which after reducing to 350 provided the best accuracy for the model. The two results show how, even with a big set of features, reducing most of them will improve the accuracy of models.
Finally, we will continue the analysis of these results in the next tab by implementing a Random Forest Classifier