Implementing a Random Forest Classifier model, following the Decision Tree conclusion and best modelling methods described on the past tab
The Random Forest Classifier generates multiple decision trees from a randomly selected subset of the training set. To predict the model collects the “votes” from different decision trees to decide the final prediction. We can see each small tree as an expert of each subset.
Code
from sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.svm import SVCfrom sklearn.metrics import ConfusionMatrixDisplay, accuracy_score, recall_scorefrom sklearn.metrics import confusion_matrixfrom tabnanny import checkfrom nltk.tokenize import TweetTokenizerimport reimport pandas as pdimport pandas as pdimport seaborn as snsimport numpy as npimport matplotlib.pyplot as pltimport matplotlib.stylematplotlib.style.use('seaborn-pastel')from nltk.tokenize import RegexpTokenizerfrom wordcloud import WordCloud, STOPWORDSimport matplotlib.pyplot as pltimport seaborn as snsimport nltkfrom nltk.probability import FreqDistfrom nltk.stem import PorterStemmerfrom sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import OneHotEncoder
C:\Users\valer\AppData\Local\Temp\ipykernel_11604\887091855.py:1: DtypeWarning: Columns (188) have mixed types. Specify dtype option on import or set low_memory=False.
df = pd.read_csv('data/endireh_ev.csv', encoding='latin1')
(73500, 354)
(73500, 354)
P12_1
P12_2
P12_3
P12_4
P12_5
P12_6
P12_7
P12_8
P12_9
P12_10
...
P4_13_4
P4_13_5
P4_13_6
P4_13_7
FAC_VIV_y.1
FAC_MUJ_y.1
ESTRATO_y.1
UPM_DIS_y.1
EST_DIS_y.1
label
0
2
1
2
3
1
3
3
8.0
8.0
3.0
...
1.0
NaN
NaN
NaN
113
113
4
1
3
1.0
1
1
1
3
3
3
1
3
1.0
2.0
4.0
...
5.0
NaN
NaN
NaN
113
113
4
1
3
0.0
2
2
1
1
3
3
3
1
3.0
8.0
1.0
...
2.0
NaN
NaN
NaN
78
155
2
2
1
0.0
3
1
1
3
1
1
1
1
1.0
2.0
3.0
...
1.0
NaN
NaN
NaN
78
78
2
2
1
0.0
4
1
1
4
3
3
3
3
8.0
8.0
3.0
...
5.0
NaN
NaN
NaN
78
78
2
2
1
0.0
5 rows × 354 columns
Code
#check balance of the classesdef check_balance(df):print(df.label.value_counts())check_balance(df)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
# Save the results in a data frame.from sklearn.metrics import classification_report, confusion_matrixdef print_report(y_test, y_pred): clf_report_linear = classification_report(y_test, y_pred, output_dict=True)print(pd.DataFrame(clf_report_linear).transpose())print_report(y_test, y_pred)
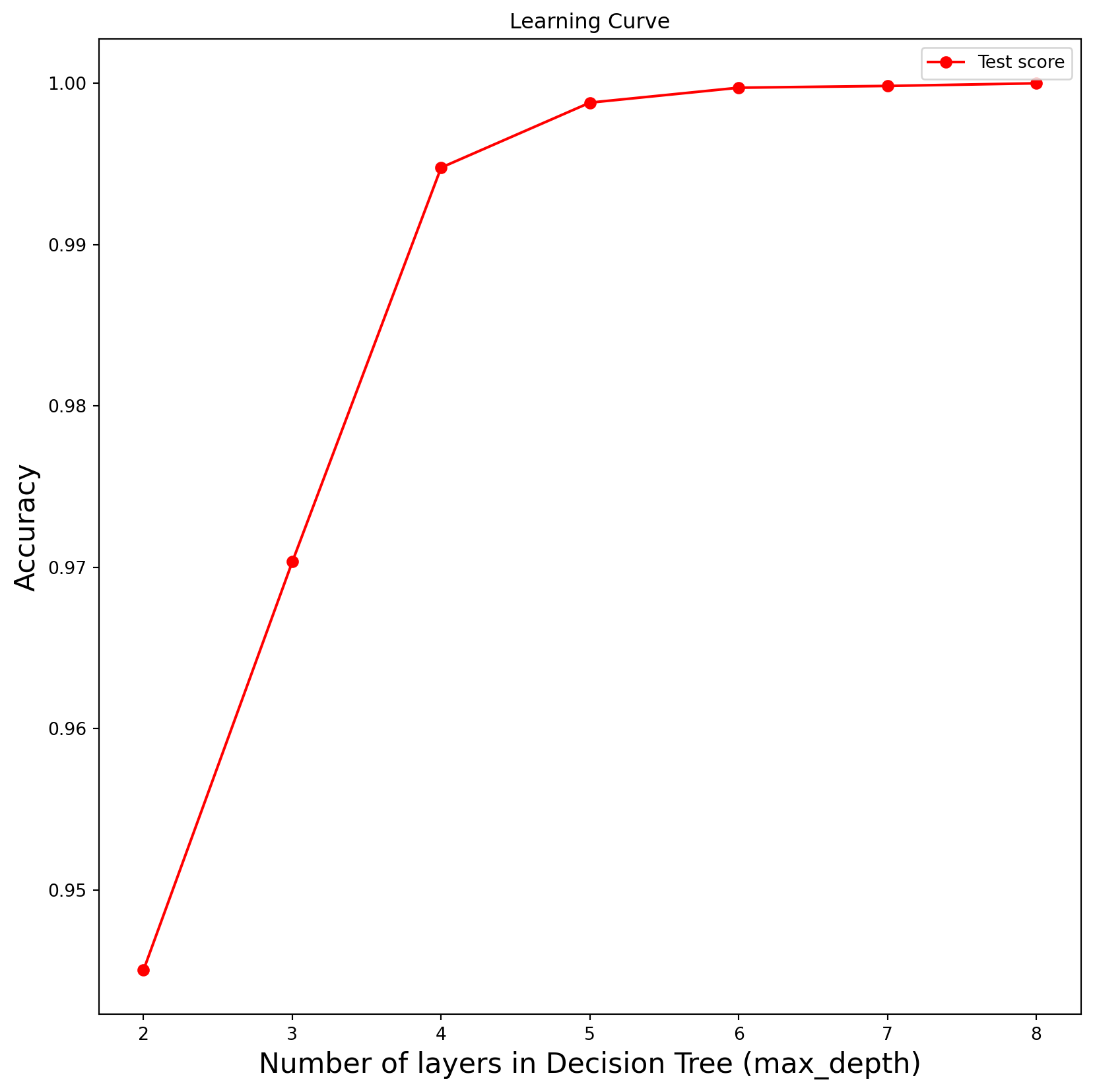
accuracy = []j =list(range(2,9))for i in j: model = RandomForestClassifier(max_depth=i, random_state=0) model.fit(X_train, y_train) y_pred = model.predict(X_test) acc = accuracy_score(y_test, y_pred)print(acc) accuracy.append(acc)
0.9450340136054421
0.9703401360544218
0.9947755102040816
0.9988027210884354
0.9997278911564625
0.9998367346938776
1.0
Even with a small number of layers the accuracy result increased in comparison with the decision tree implementation
Code
plt.subplots(1, figsize=(10, 10))plt.plot(j, accuracy,label="Test score", color="red",marker="o")plt.title("Learning Curve")plt.xlabel("Number of layers in Decision Tree (max_depth)",fontsize=16), plt.ylabel("Accuracy",fontsize=16), plt.legend(loc="best")plt.show()
From the plot we can see that the max depth parameter is similar to the single decision tree we performed before, so we are keeping the value as 7 for our best model
Code
model = RandomForestClassifier(max_depth=7, random_state=0)model.fit(X_train, y_train)y_pred = model.predict(X_test)print_report(y_test, y_pred)
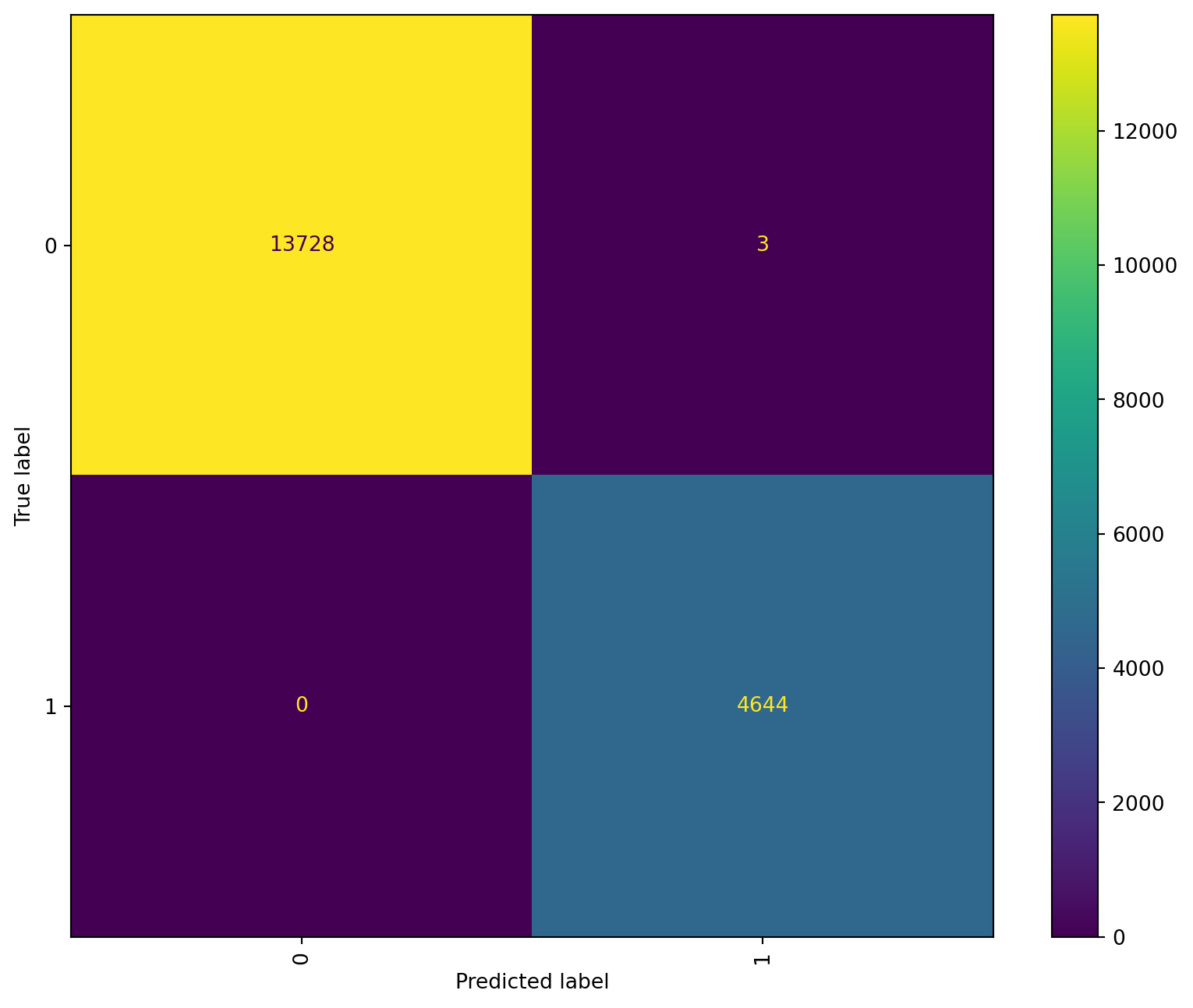
After looking at the results we can conclude Random Forest Classifier outperformed a single Decision Tree, after training with our data, obtaining a total accuracy of 99.7%
Even though the accuracy is closer to 100% we should evaluate the performance of the model because there might be an overfitting. Looking closely into the results, specially at the confussion matrix we can observe how the model is predicting correctly on False Negatives. Which is why recall in Negatives is not a 100%.
Analyzing social data is not easy, specially on sensitive topics like violence. Training a model with our data is making the model not capable of detecting when a women has not experienced emotional violence; this was an unexpected behavior since we have an unbalanced set with more data points labeled as “0” thus we would have expected the model overfitting on that class.
As next steps would be to bring back the data we dropped to test the model and see how it behaves, it would also be interesting to tune the model to not be unbalanced towards an specific class or understand if certain features are actually causing this behavior.