Naive Bayes is a classification technique based on Bayes Theorem, it assumes independence among features. Some of the advantages of this model used for text classification are: it’s simplicity and the small amount of resources for training, which becomes useful with the “long” datasets generated by tokenizing texts.
Evaluation metrics
Different evaluation metrics will be used to compare the model’s prediction to a test set that will be randomly obtained:
Accuracy: (TP + TN) / TN . Which states the number of correctly predicted data points out of all the data point
Recall: TP / (T P+ FN) . Which measures of all the data points, how many of those we correctly predict?
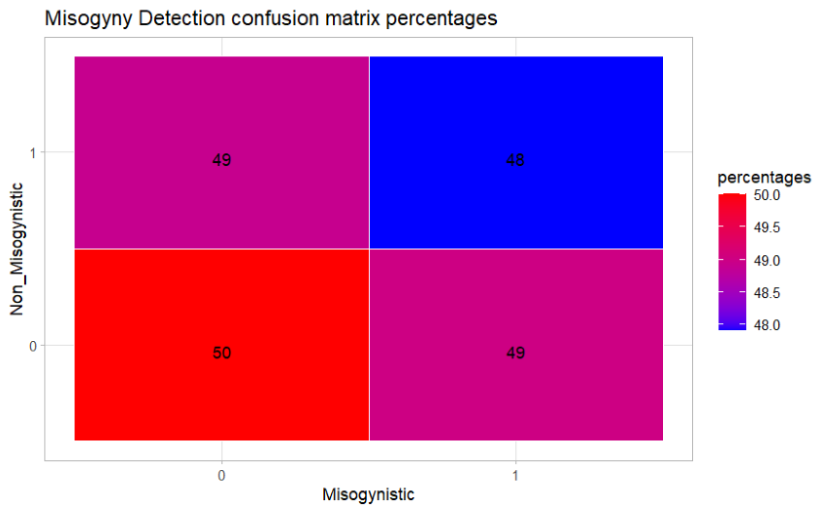
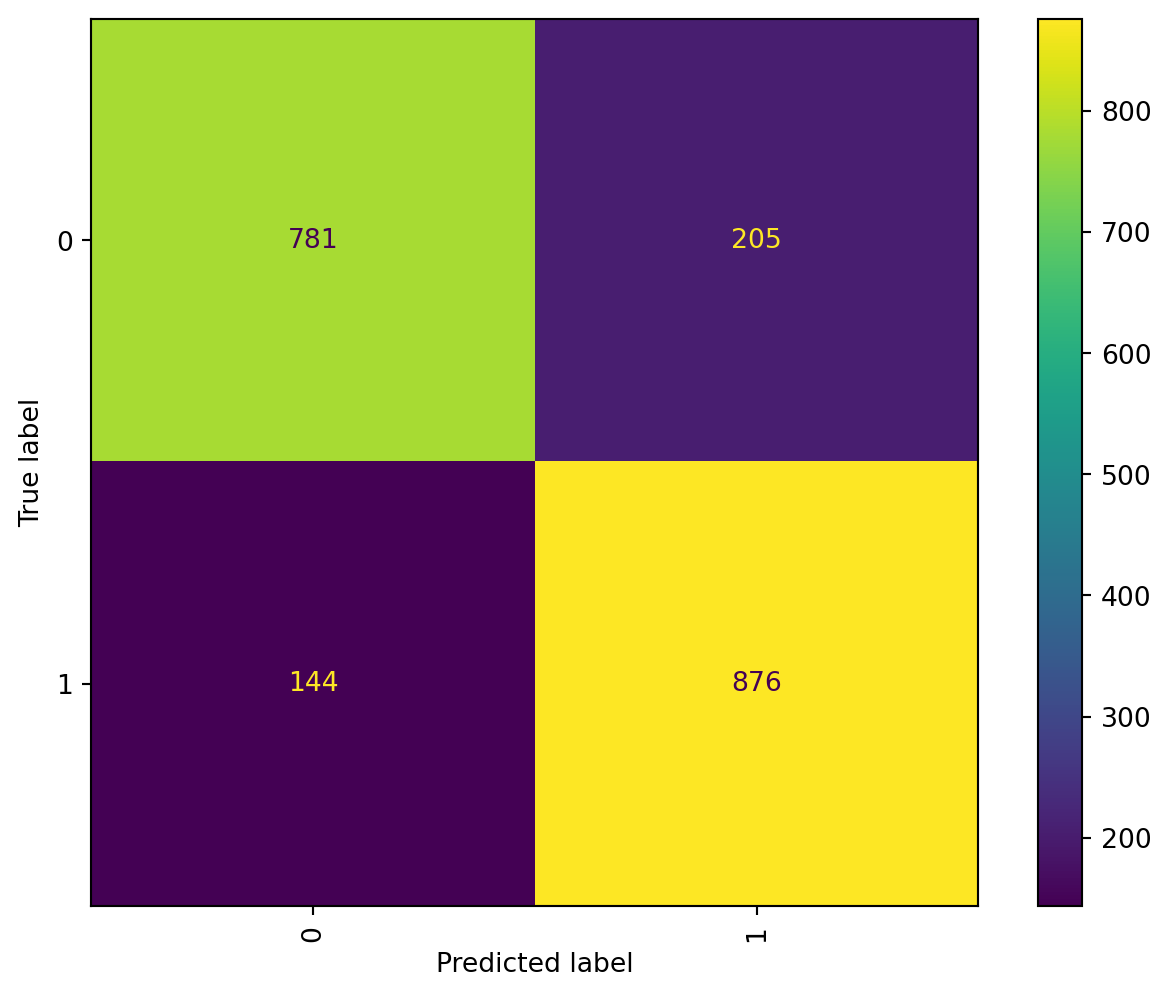
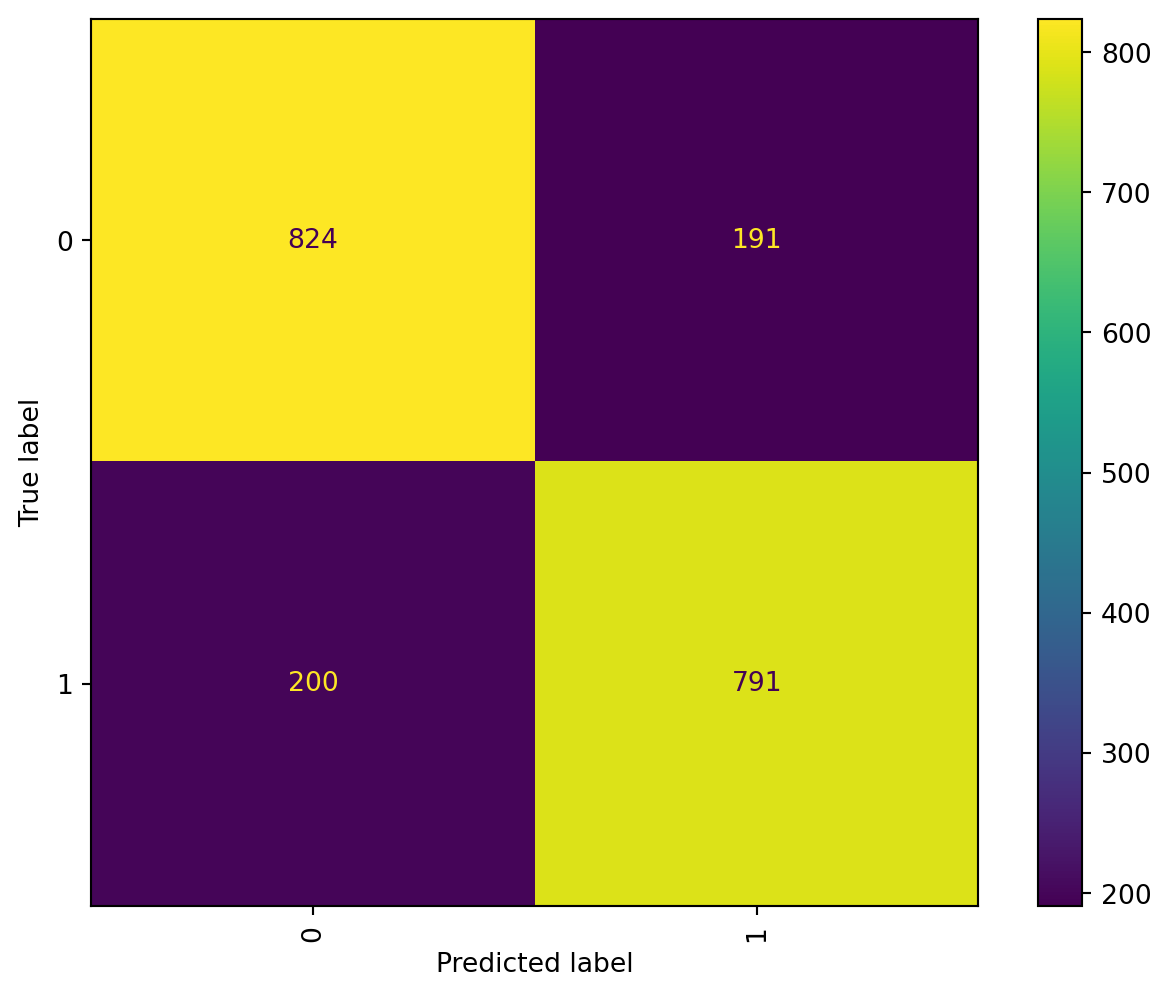
Confusion Matrix: Table layout that visualizes of the performance of a model. It will be separated into 4. Each row of the matrix represents the instances in an actual class while each column represents the instances in a predicted class. It represents the correct misogynistic value TP correct non - misogynistic value TN, the incorrect misogynistic values FP and the incorrect non-misogynistic values FN.
Implementation
Even though last phases went through a cleaning and exploring phase, the training experiment aims to test multiple preprocessing techniques, that can be considered part of the “cleaning” section but it is important to repeat them before each training, and evaluate the accuracy of the model to understand which one works better on our dataset.The data was labeled as 1 for misogynistic texts and 0 as non-misogynistic, thus the classification was a binary one.
Language model
The language in our dataset will be represented through a Bag Of Words (BOW) model, which is a simple representation used in natural language processing. It is an orderless document representation where the metric for each word will be the counts of words per text, in this work, per tweet.
Implementation in R
First an R markdown script does a random splitting of the data following a 80% training set and 20% for testing. The data has a balanced set of a bit more than 10,000 short texts in Spanish.
After splitting the data the script cleans and models it. The cleaning phase and bag of words creation utilizes multiple packages to implement multiple preprocessing and cleaning techniques that have demonstrated to improve the performance of models in multiple projects, specially in classifiers dealing with texts in Spanish, such as:
Finally the data is ready to serve as an input to the Bayes model; The Bayes model in R receives both the train set and the labels which makes it a model capable to make predictions to our test data.
Code
model <- naive_bayes(y = factor(train$label), x = X_train, usekernel = TRUE) p <- predict(model, X_test, type = 'prob')
Once the model has predicted the testing data, we can move on to “measure” it’s performance against the correct labels.
Finally, the classifier will be trained again with a different word’s model, the first one used only 1 n-gram and the second classifier will be trained with a bigram modelling:
Code
X_train_bi = create_bow(train$text,3)X_test_bi = create_bow(test$text,3)model <- naive_bayes(y = factor(train$label), x = X_train) p <- predict(model, X_test_bi, type = 'prob')
R results
Two models were trained in R; both of them went through the same cleaning techniques but the first one received the data modeled through a 1 n-gram or “unigram” modelling and the second one through “bigrams”. Unfortunately, neither of the two models obtained a good accuracy result. The n-gram function in R was not capable of tokenizing the bigrams for our texts thus, the model performed exactly as the unigrams. Looking at the unigram model results we can tell it did not obtained good
printing the model in R provides a description of the model metrics. We can see how it behaves better for the misogynistic texts with an a priori probabilities of 49.01 for non-misogynistic texts and 50.003 for misogynistic ones. Which is not a good metric in terms of prediction.
To understand a little bit more about the problem the Bayes model was implemented also through the caret function. Although the accuracy this model provided was the same as the R NB model with 50.01%-
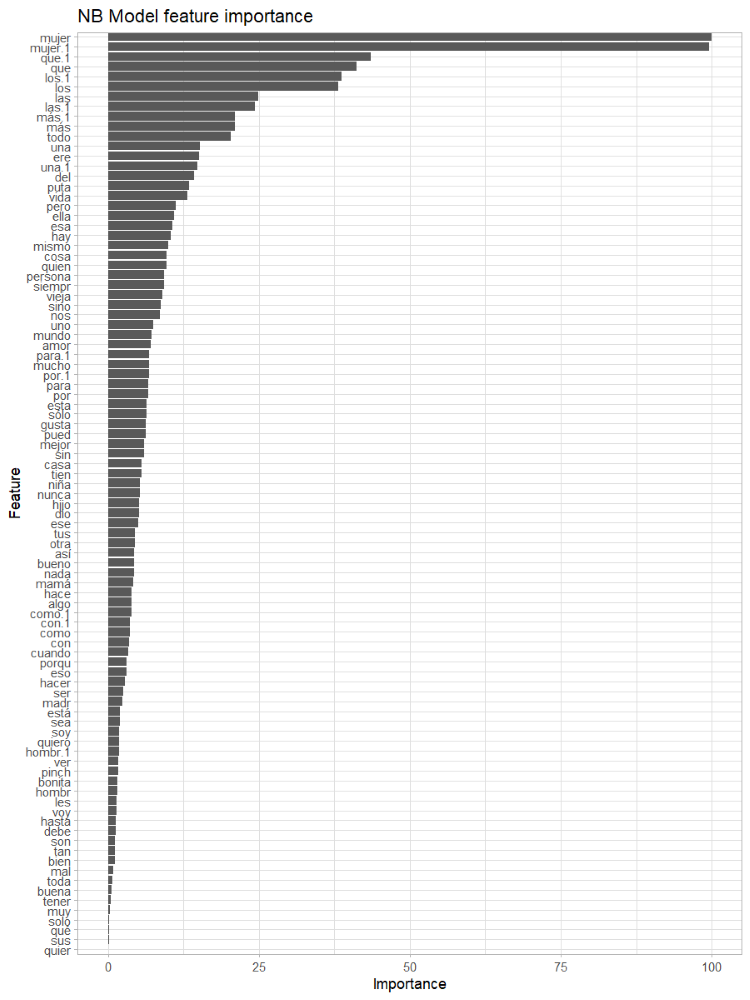
Through the usage of this package we also evaluated the most important features for the model, and it’s level of importance. Plotting feature importance
Code
p <- ggplot(top)p + theme(axis.text.y = element_text(size=7)) + scale_x_discrete(expand=c(.000000, 0.2))+ ggtitle("NB Model feature importance")+theme_light()
The feature importance result makes sense, since “woman” was the most important word, by more than 20%. An important thing to look at is the rest of the words among the feature importance. Most of them are stopwords, while some of the stopwords might provide important value since those express gender towards the subject, some could also be removed and the model might improve.
Implementation in python
On this language the data is also preprocessed with multiple techniques. Firstly, it is only cleaned, tokenized and represented (also through the tf-idf measure). This data was used to trained two models: a Gaussian Naive Bayes (GNB) and a Multinomial NB, both implemented through sklearn.
ACCURACY CALCULATION
TRAINING SET:
Accuracy: 0.6769690927218345
Number of mislabeled points out of a total 2508 points = 648
RECALL :
0.840122199592668
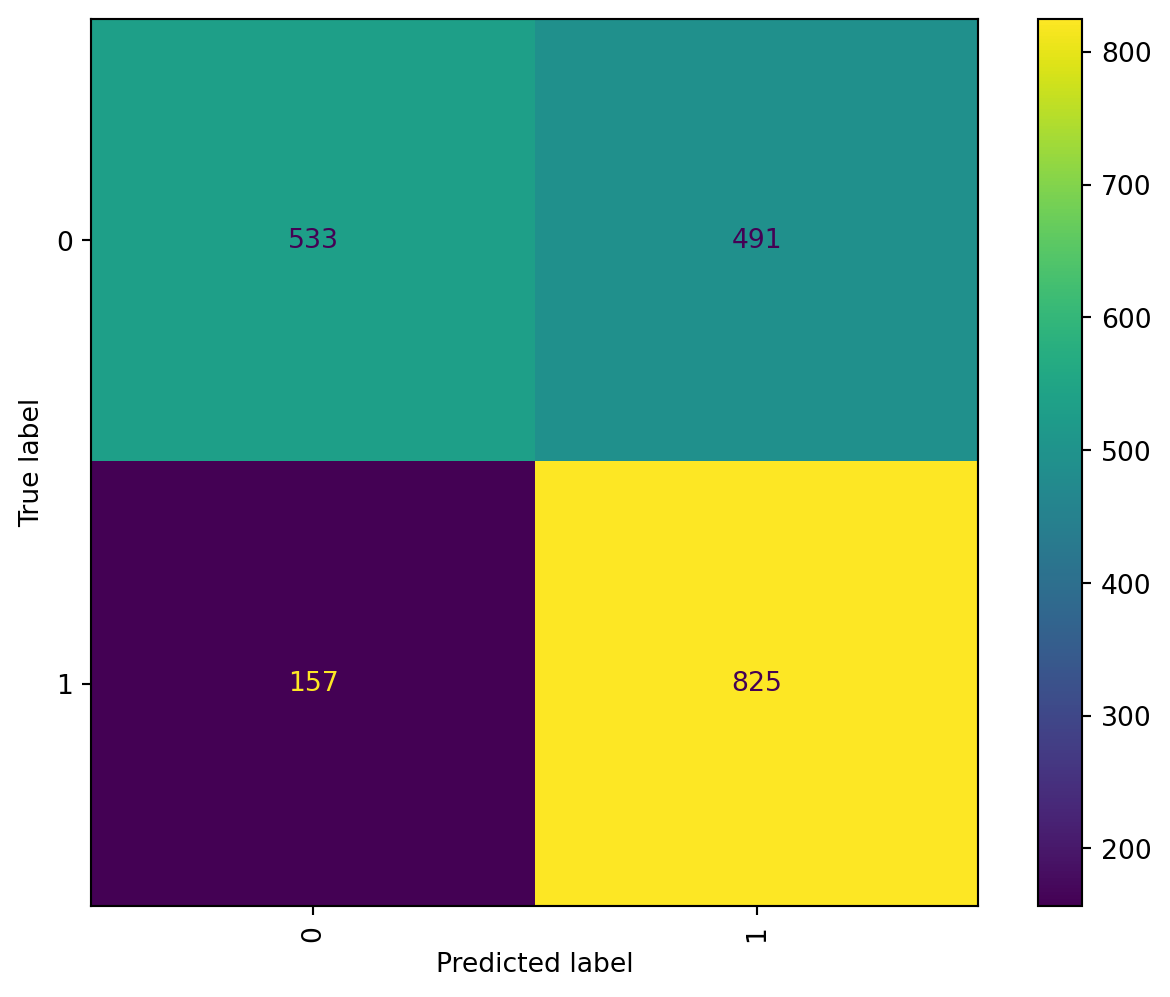
As expected the Gaussian NB didn’t perform well since it assumes the features would follow a normal distribution. which is not the case of a bow, with thousands of features distributed with longer tails. this model returned an accuracy of 68.18% .
Although the accuracy was not great, from the confusion matrix we can tell the model provides a good result in True Positives, which would be an important score to aim, since we want the model to correctly interpret whenever a misogynistic conversation happened.
ACCURACY CALCULATION
TRAINING SET:
Accuracy: 0.6769690927218345
Number of mislabeled points out of a total 2508 points = 648
RECALL :
0.840122199592668
On the other hand Multinomial NB improved the accuracy of the Gaussian model by more than 10% obtaining a total accuracy of 80.90%. The model replicates the behavior of Gaussian NB by having the best result among true positives.
The total number of mislabeled points were 479 , being 193 False positives and 286 False negatives. which means the classifier is better detecting a misogynistic text rather than a not misogynistic text. For this analysis we also obtained the recall result with the MNB model ehich was 84.23, which on violence detection applications might be more important than measuring accuracy.
Implementation with bigrams
Multiple techniques have been defined across the Natural Language Processing field to improve the representation of the language for text classifiers, one of the most utilized techniques to solve one of the biggest disadvantages of the BoW model is utilizing bigrams. Normally a bag of word would loose all the context of the text order, through bigrams we can retain a bit more.
ACCURACY CALCULATION
TRAINING SET:
Accuracy: 0.8260219341974078
Number of mislabeled points out of a total 2508 points = 349
RECALL :
0.8588235294117647
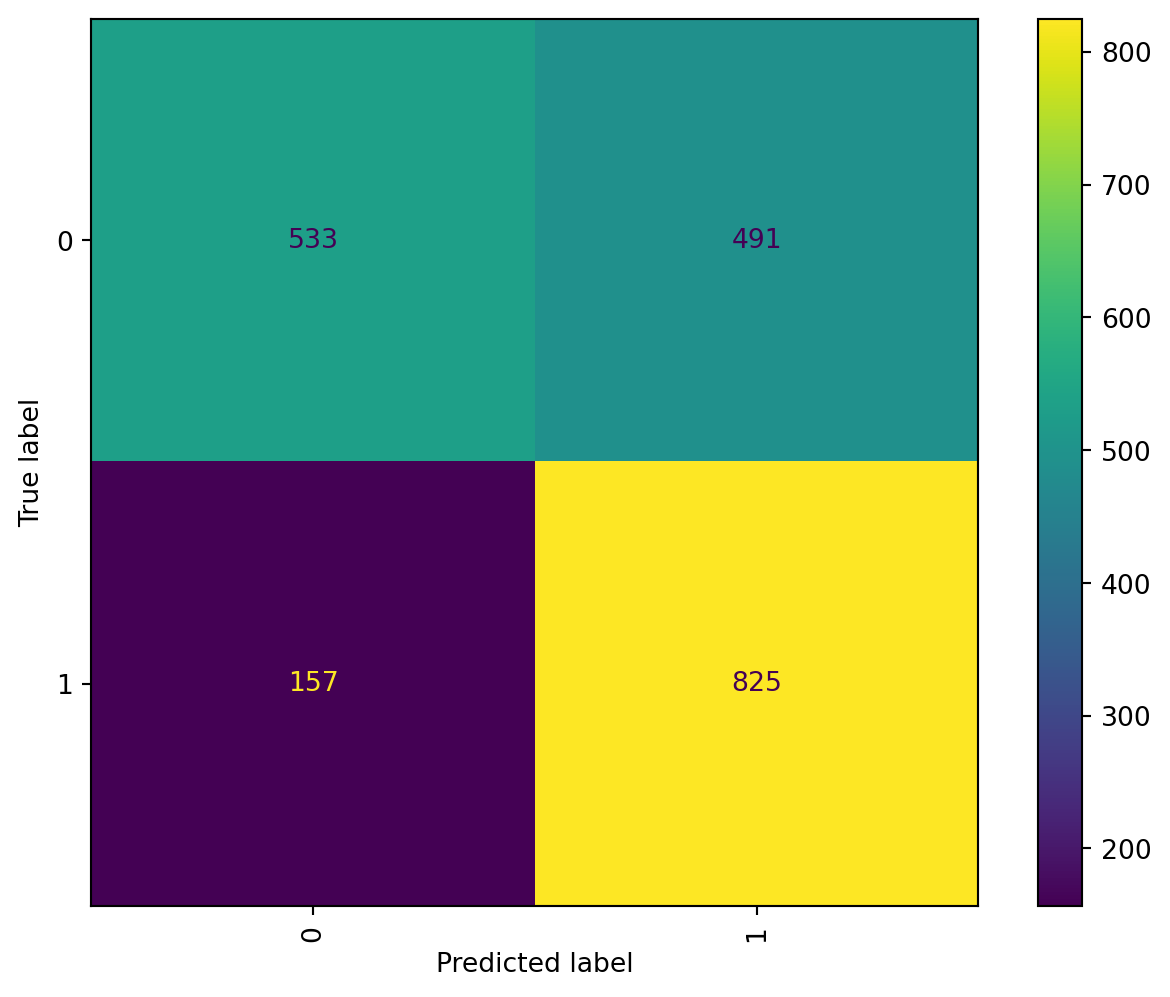
After modelling the data with bigrams, the MNB improved it’s accuracy by 2% with a total of 82.85%, which is a slight but useful increase. The recall also increase, following the same behavior of the model, increasing in 2%
Implementation with stemming
Moving forward with other techniques although, there are plenty to continue experimenting, Unfortunately most tools doesn’t have accurate transformers for spanish texts. For example, Spacy mentions it has a 95% of accuracy for lemmatization in english but it doesn’t have an accuracy percentage in spanish, specially spanish from Latin America since most of it’s lemmas work with spanish from Spain verb’s flex forms for example, “correr” which is run on it’s plural form in Latin America would be “corren” and in Spain would be “corréis”.
Since most state of the art projects mention that lemmatization doesn’t improve the accuracy of the model we decided to go with stemming. for this method we used the Snowball stemmer in spanish.
Code
from nltk.stem import SnowballStemmerdef stemming(df): stemmer = SnowballStemmer("spanish") stemmed_text = []for tweets in df["clean_text"]: tweet = tweets.split(" ") stemmed_word =""for word in tweet: stemmed_word += stemmer.stem(word)+" " stemmed_text.append(stemmed_word) df["stemmed_text"] = stemmed_textstemming(df)df.head(2)
ACCURACY CALCULATION
TRAINING SET:
Accuracy: 0.8050847457627118
Number of mislabeled points out of a total 2508 points = 391
RECALL :
0.798183652875883
After implementing an Snowball stemming technique and looking at the results we found this technique didn’t help our classifier, actually, it slightly decreased from the first accuracy we obtained, with a total of 80.50% which could be related to the lack of accuracy on the R model since we utilized the same technique.
Besides the loss of accuracy it is important to look at the recall value which is 85.81%, in comparisson with the rest of the models, using stemming actually changed the behavior of the model. this might be related to the truncation of the words, we can assume the classifier helps itself to improve its detections through the “subject” information found in verbs or adjectives that might be truncated.
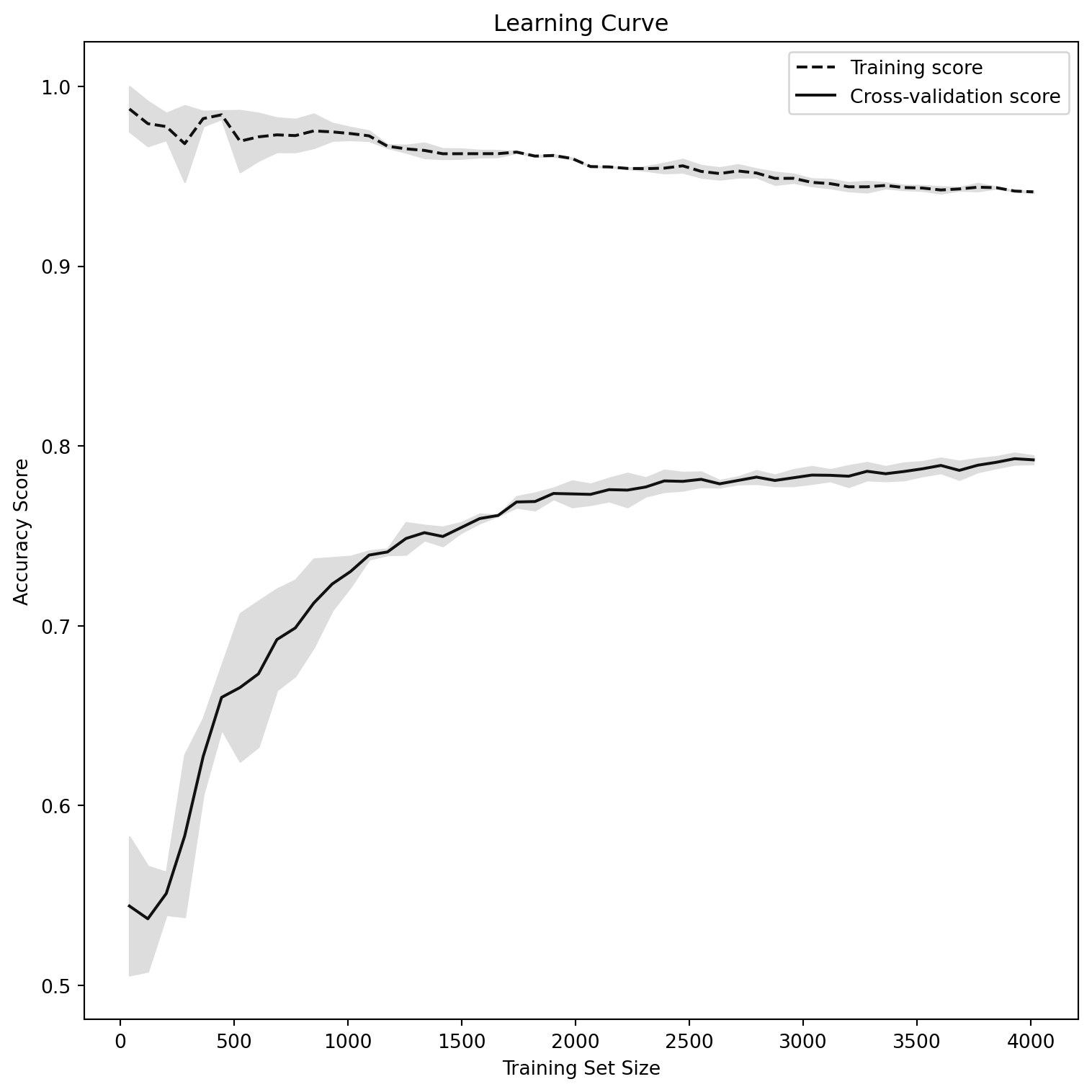
Finally, we also wanted to have a clear idea of the model without the bias of the testing set selection, for this the learning curve was plotted to analyze how accuracy increases or decreases depending on the data is testing on. For this we utilized the cross-validation technique to test with our whole dataset.
From the learning curve we can see how the accuracy improves with the increase of data on the training set, and it maintains around 2,500 texts entries. it is also important to see that wth a fix data set the accuracy is pretty high but the accuracy wth cross-validation after 4,000 tweets gets closer into the same space, thus we can considered our model is not biased by the testing set split.