The objective of using the unsupervised ARM task in this page is to do an exploratory analysis of the tweets set labeled as misogynistic or not to understand and analyze the relations of co-occurrence and patterns among the texts. Although ARM task is an unsupervised one, the labels of the set will be taken as an advantage to compare it as two different sets.
Model
The Association rule mining is an unsupervised rule-based machine learning method. This rule shows how frequently a item set occurs in a transaction and its objective is to discover statistically relevant relationships between variables in large sets. To anticipate the occurrence of an item based on the occurrences of other items in the training data, find rules that will work with a particular group of transactions in a set. Since market basket analysis was the initial application of association mining, association rule mining is occasionally referred to as “market basket analysis.”
The ARM works with the “Apriori” algorithm, the rules are calculated from itemsets, which are made up of two or more items. The algorithm identifies the most frequent individual items in the set, extending to obtain more and more relations or itemset. Extending the relations might be negative since it can lead to having a large number of rules that could make the model computationally inefficient.
Hyperparameter
The threshold or min-support can be used to reduce the number of possible rules to obtain the most important ones or “remove” the least important, improving the model’s efficiency.
Evaluation Metrics
To evaluate how an itemset or relation that contains A and B can be more frequent or occurs more strictly than other three evaluation metrics will be taken in consideration:
Support: How often do items A and B occur together relative to all other transactions? It measures how common the occurrence is from 1 to 0.
Confidence: How often items in A and items in B occur together, relative to transactions that contain A. Measures how statistically strict a rule is from 1 to 0.
Lift: Ratio of the observed support to that expected if X and Y were independent. It measures if those are independent, negatively, or positively related.
Code
import nltkimport stringfrom nltk.stem import WordNetLemmatizerfrom nltk.stem import PorterStemmerfrom nltk.corpus import stopwordsfrom nltk.tokenize import word_tokenizefrom nltk.sentiment import SentimentIntensityAnalyzerimport osimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom apyori import aprioriimport networkx as nx #import downloadnltk.download('vader_lexicon')nltk.download('stopwords')nltk.download('wordnet')nltk.download('punkt')nltk.download('omw-1.4')
[nltk_data] Downloading package vader_lexicon to
[nltk_data] C:\Users\valer\AppData\Roaming\nltk_data...
[nltk_data] Package vader_lexicon is already up-to-date!
[nltk_data] Downloading package stopwords to
[nltk_data] C:\Users\valer\AppData\Roaming\nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package wordnet to
[nltk_data] C:\Users\valer\AppData\Roaming\nltk_data...
[nltk_data] Package wordnet is already up-to-date!
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\valer\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package omw-1.4 to
[nltk_data] C:\Users\valer\AppData\Roaming\nltk_data...
[nltk_data] Package omw-1.4 is already up-to-date!
True
Reading and cleaning the tweets. Three sets will be generated, one with cleaning techniques, a second one without stop-words and a third one applying stemming
Code
from nltk.tokenize import TweetTokenizerimport pandas as pdimport numpy as npimport refrom nltk.stem.snowball import SnowballStemmer
Code
#obtaining tweets as dfdf = pd.read_csv("data/clean_set.csv")clean_text = []replace = [ (r"<a[^>]*>(.*?)</a>", " url"), (r"@[a-zA-Z0-9_]{0,15}", " user"), (r"_[a-zA-Z0-9_]{0,15}", " user"), (r"#\w*[a-zA-Z]\w*", " hashtag"), (r"(?<=\d),(?=\d)", ""), (r"\d+", "number"), (r"[\t\n\r\*\.\@\,\-\/]", " "), (r"\s+", " "), (r'[^\w\s]', ''), (r'/(.)(?=.*\1)/g', ""), (r'http[^\s]*',""), (r'(.*)\bt\b(.*)',""), (r'(.*)\bco\b(.*)',"") ]#df[text] is column with each row is a tweet in stringfor text in df["text"]:for rp in replace: text = re.sub(rp[0],rp[1], text) clean_text.append(text.lower())#clean text is now a list with clean tweetsstemmer = SnowballStemmer("spanish")tk = TweetTokenizer()stops =set(stopwords.words('spanish'))#transactions list of liststransactions = [tk.tokenize(x) for x in clean_text]transactions_sw_st= []transactions_sw= []for text in transactions: transactions_sw_st.append([stemmer.stem(x) for x in text if x notin stops]) transactions_sw.append([x for x in text if x notin stops])
Functions to plot the network and obtain the metrics
Code
def reformat_results(results): keep=[]for i inrange(0,len(results)):for j inrange(0,len(list(results[i]))):if (j>1):for k inrange(0,len(list(results[i][j]))):if(len(results[i][j][k][0])!=0): rhs=list(results[i][j][k][0]) lhs=list(results[i][j][k][1]) conf=float(results[i][j][k][2]) lift=float(results[i][j][k][3]) keep.append([rhs,lhs,supp,conf,supp*conf,lift])if(j==1): supp=results[i][j]return pd.DataFrame(keep, columns=['rhs','lhs','supp','conf','supp x conf','lift'])def convert_to_network(df):#BUILD GRAPH G = nx.DiGraph() # DIRECTEDfor row in df.iterrows():# for column in df.columns: lhs="_".join(row[1][0]) rhs="_".join(row[1][1]) conf=row[1][3];#print(conf)if(lhs notin G.nodes): G.add_node(lhs)if(rhs notin G.nodes): G.add_node(rhs) edge=(lhs,rhs)if edge notin G.edges: G.add_edge(lhs, rhs, weight=conf)# print(G.nodes)# print(G.edges)return Gdef plot_network(G,title):#SPECIFIY X-Y POSITIONS FOR PLOTTING pos=nx.random_layout(G)#GENERATE PLOT fig, ax = plt.subplots(dpi=120,) fig.set_size_inches(15, 15)#assign colors based on attributes weights_e = [G[u][v]['weight'] for u,v in G.edges()]#SAMPLE CMAP FOR COLORS cmap=plt.cm.get_cmap('PuRd') colors_e = [cmap(G[u][v]['weight']*10) for u,v in G.edges()]#PLOT nx.draw( G, edgecolors="white", edge_color=colors_e, node_size=2000, linewidths=2, font_size=8, node_color="pink", font_color="black", width=weights_e, with_labels=True, pos=pos, ax=ax ) ax.set_title(title, fontsize=20) plt.show()
Experimenting with different support values. The bigger the value, the smaller the number of connections to obtain.
Code
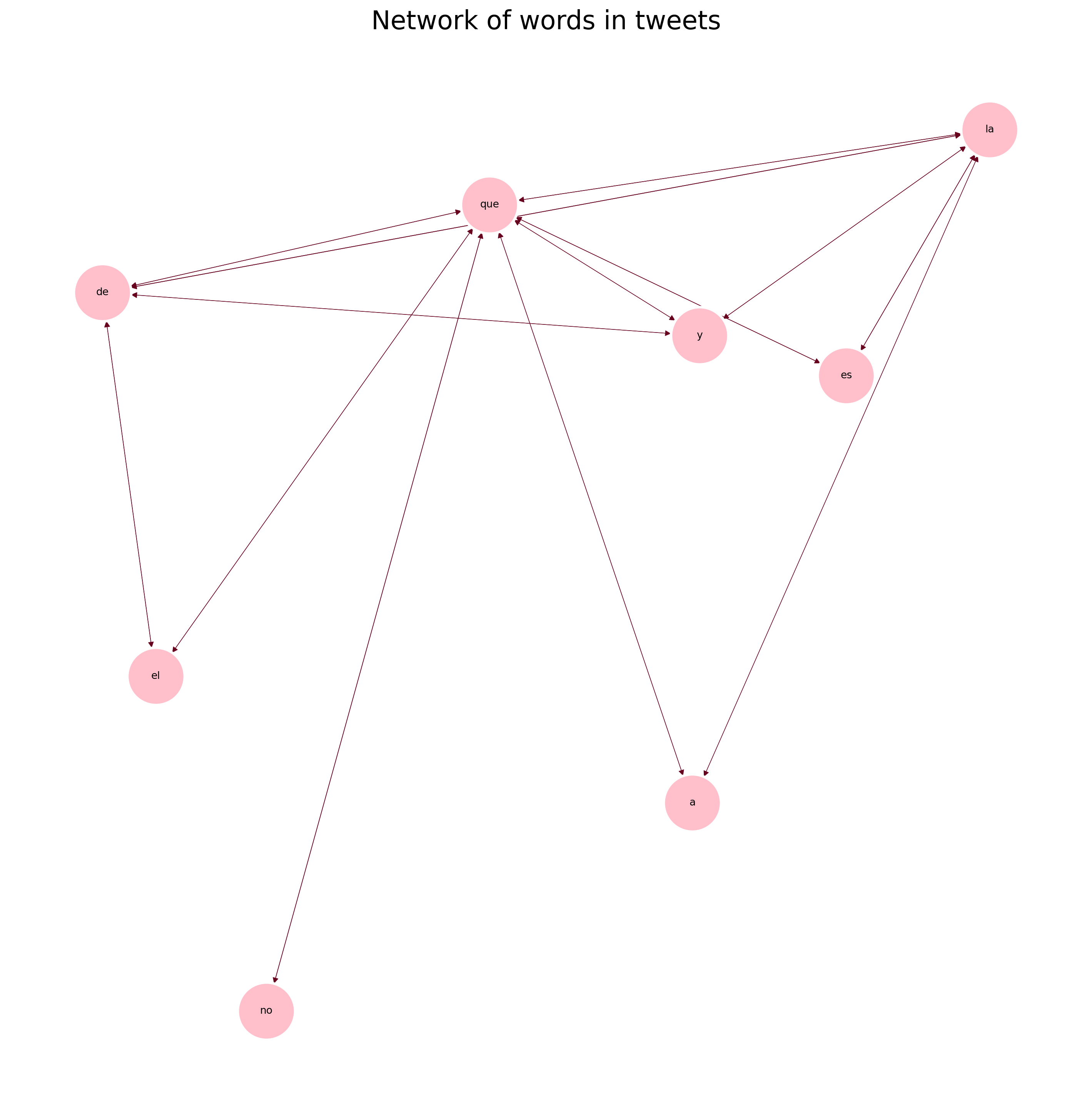
results =list(apriori(transactions,min_support =0.1,min_confidence=.03,min_length=1,max_length=5))pd_results=reformat_results(results)G=convert_to_network(pd_results)plot_network(G, 'Network of words in tweets')print(pd_results[0:5])
All of the connections generated are stop words in spanish, thus the importance of removing them.
Code
results =list(apriori(transactions_sw,min_support =0.001,min_confidence=.03,min_length=1,max_length=5))pd_results=reformat_results(results)G=convert_to_network(pd_results)plot_network(G, 'Network of words in tweets')print(pd_results[0:10])
After removing the stopwords more significant words are showing. Having a small support generates too many connections which are hard to appreciate through the plot. Therefore the number will be increased.
Code
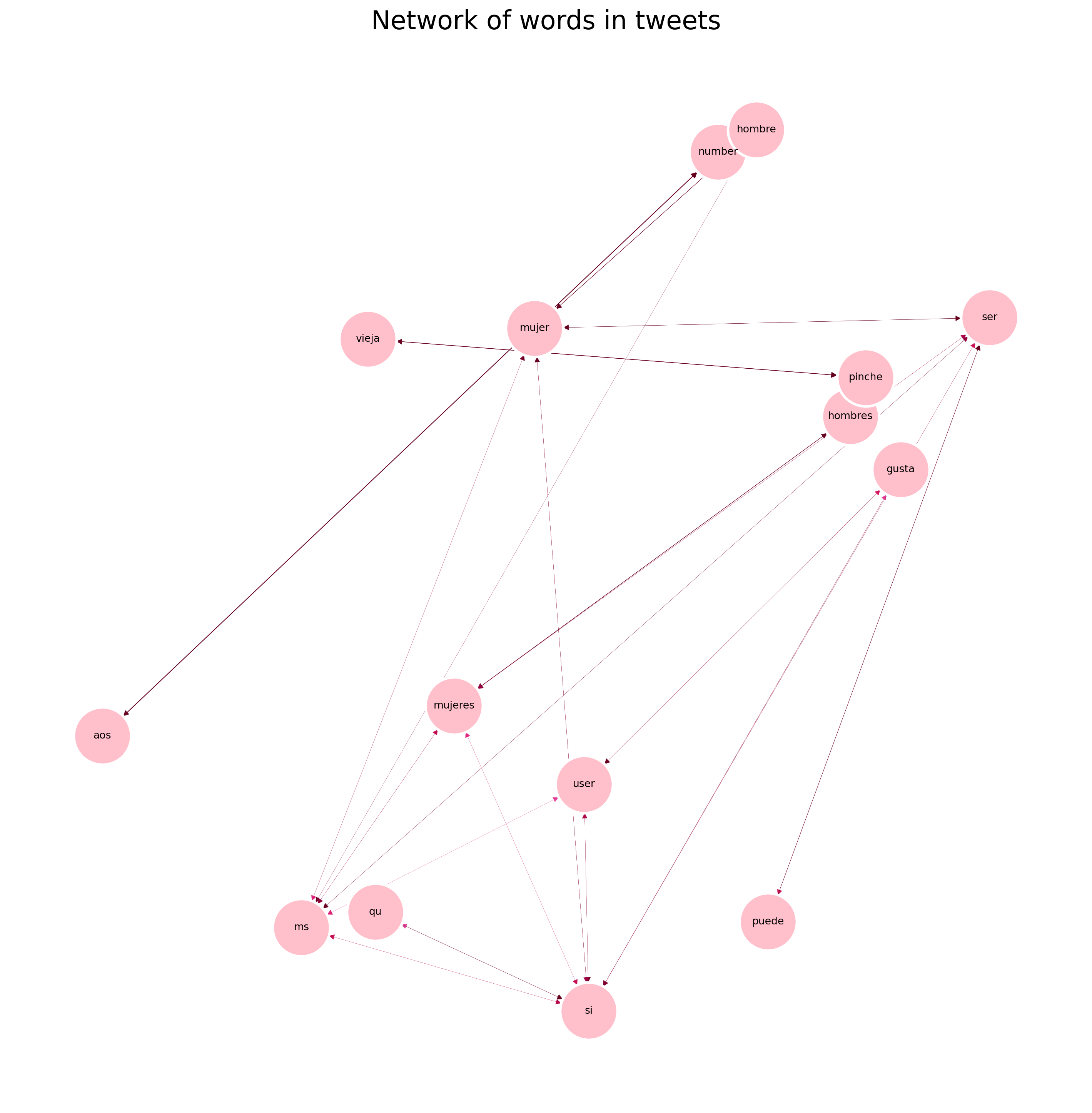
results =list(apriori(transactions_sw,min_support =0.004,min_confidence=.03,min_length=1,max_length=5))pd_results=reformat_results(results)G=convert_to_network(pd_results)plot_network(G, 'Network of words in tweets')print(pd_results[0:5])
Now we can see how the dataset connections are related to gender pronouns such as “hombre” man and “mujer” women and their plurals. The stemming set will be used to solve the problem of grouping plurals and singulars.
The support and confidence also dropped since the stopwords appear more frequently together.
Code
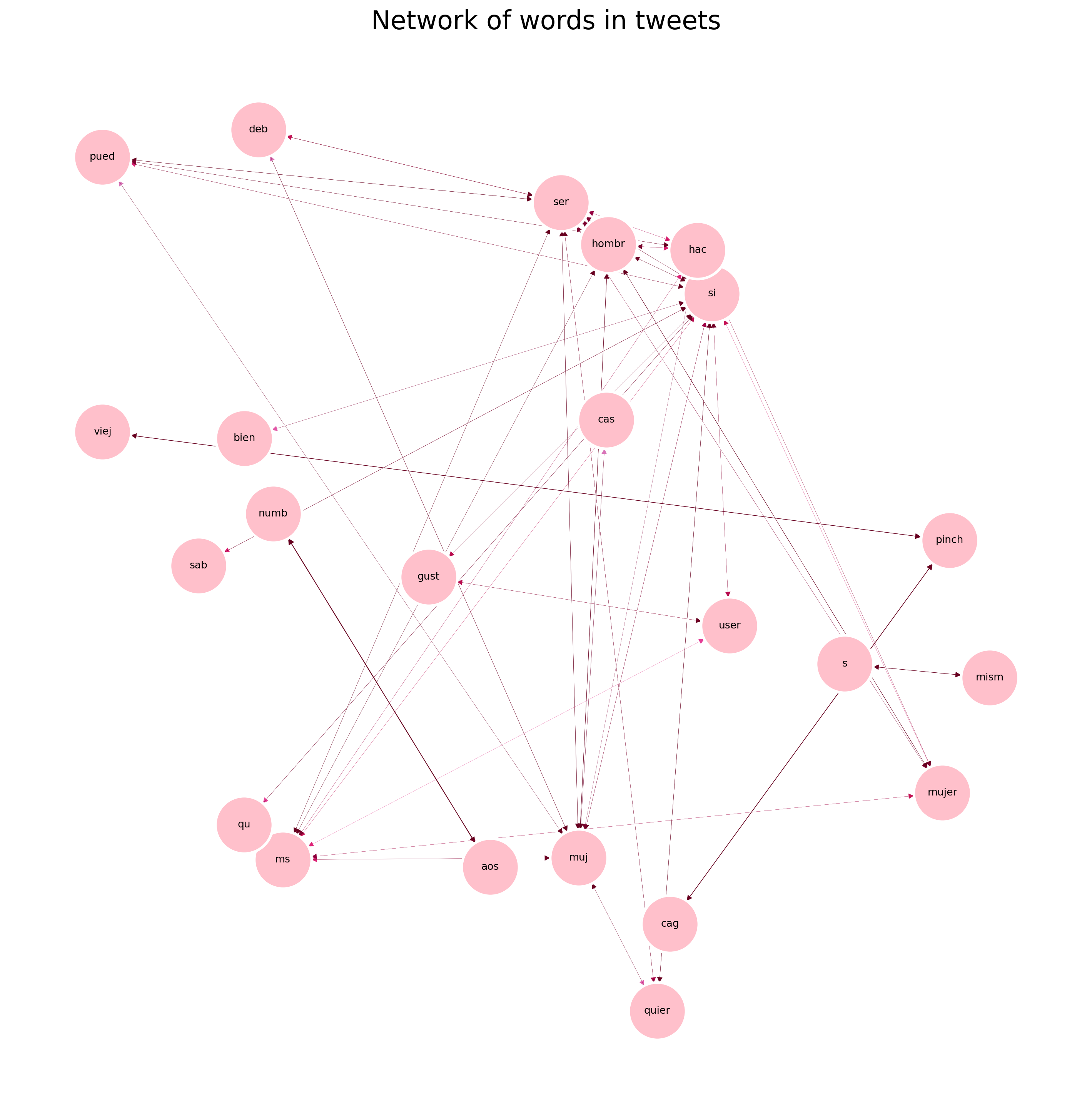
results =list(apriori(transactions_sw_st,min_support =0.004,min_confidence=.03,min_length=1,max_length=5))pd_results=reformat_results(results)G=convert_to_network(pd_results)plot_network(G, 'Network of words in tweets')print(pd_results[0:5])
Stemming did not perfom as good since the words are “truncated” thus the nouns in singular such as mujer was reduced to muj and plural to mujer. The lemmatizing technique should solve this problem. Unfortunately different works have shown recent packages do not perform well on spanish texts.
Misogynistic vs non-misogynistic
Finally, a comparison between the networks of misogynistic and non-misogynistic tweets will be performed.
Code
#separating data by labelno_miso_indx = df.index[df['label'] ==0].tolist()miso_indx = df.index[df['label'] ==1].tolist()transactions_miso= [transactions_sw[x] for x in miso_indx]transactions_no_miso= [transactions_sw[x] for x in no_miso_indx]
Code
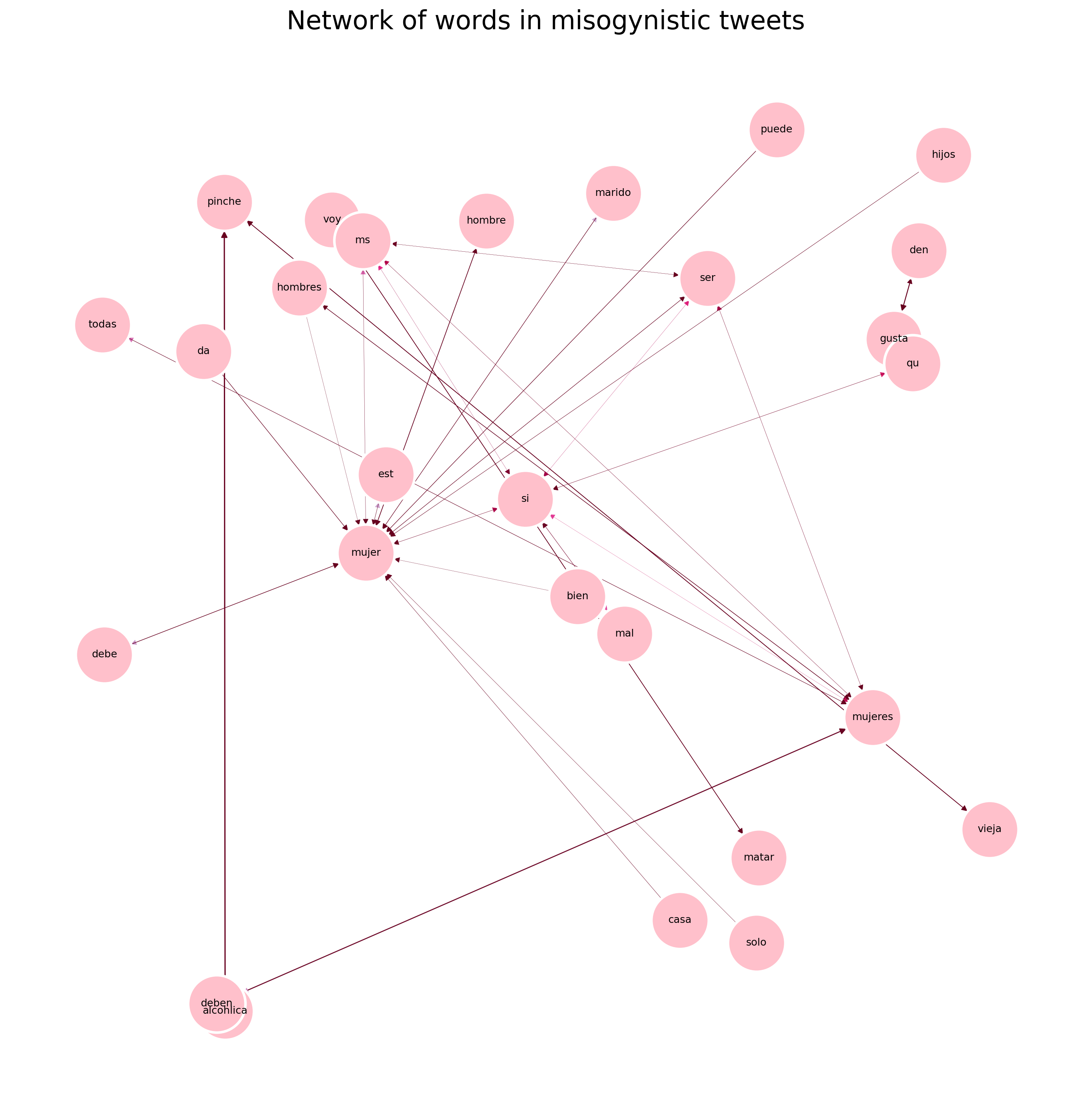
results =list(apriori(transactions_miso,min_support =0.004,min_confidence=.03,min_length=1,max_length=5))pd_results=reformat_results(results)G=convert_to_network(pd_results)plot_network(G, 'Network of words in misogynistic tweets')print(pd_results[0:10])miso_results=pd_results
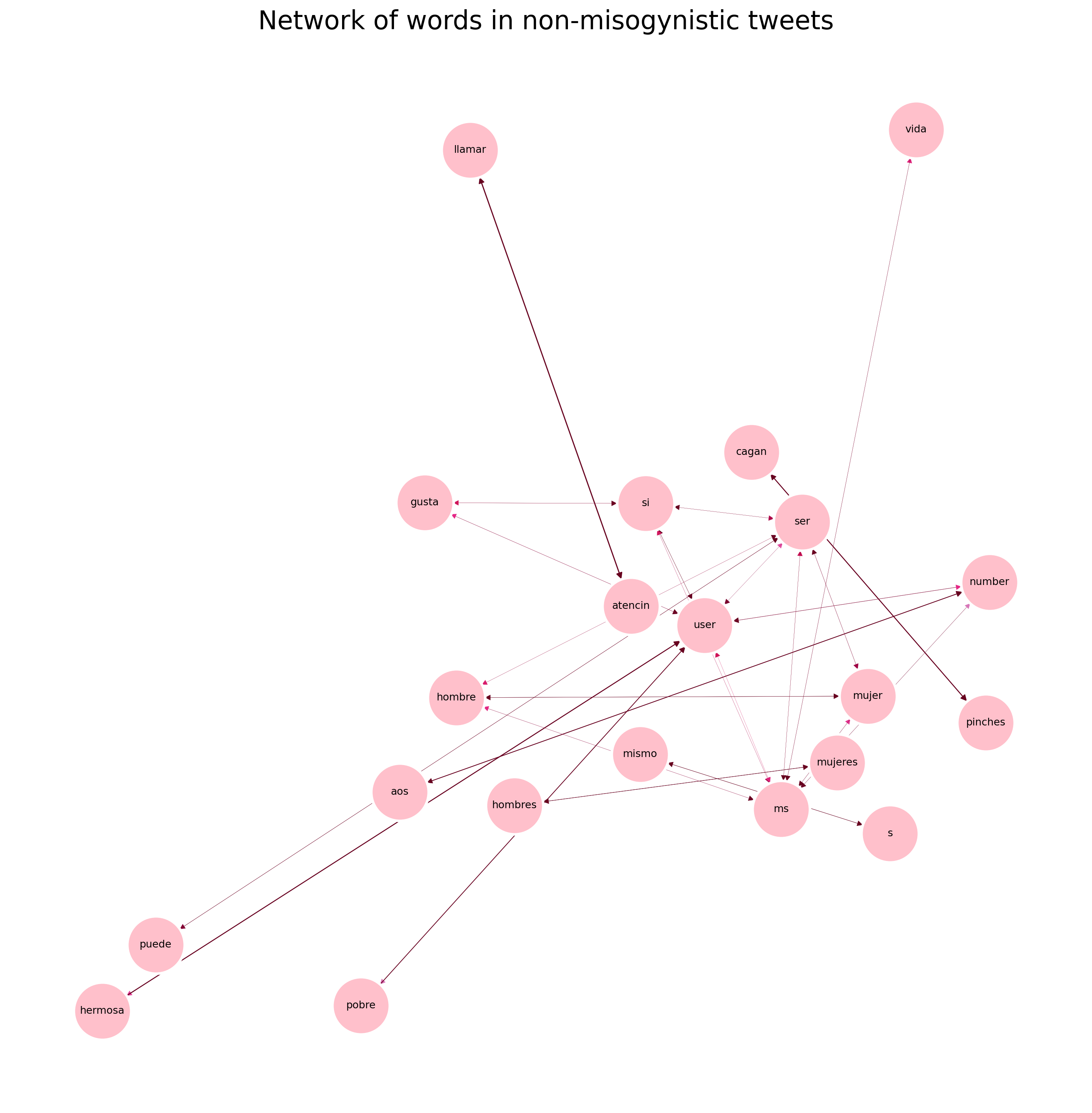
results =list(apriori(transactions_no_miso,min_support =0.004,min_confidence=.03,min_length=1,max_length=5))pd_results=reformat_results(results)G=convert_to_network(pd_results)plot_network(G, 'Network of words in non-misogynistic tweets')print(pd_results[0:10])no_miso_results=pd_results
A difference of connections is observed between the networks. In general the set contains tweets where the words man and women mostly appear together which might be related to comparisons either positive or negative among the two genders.
On the other hand misogynistic and non-misogynistic tweets have different types of connections. Both with a total variance of 0.004 had a similar number of relations, around 50.
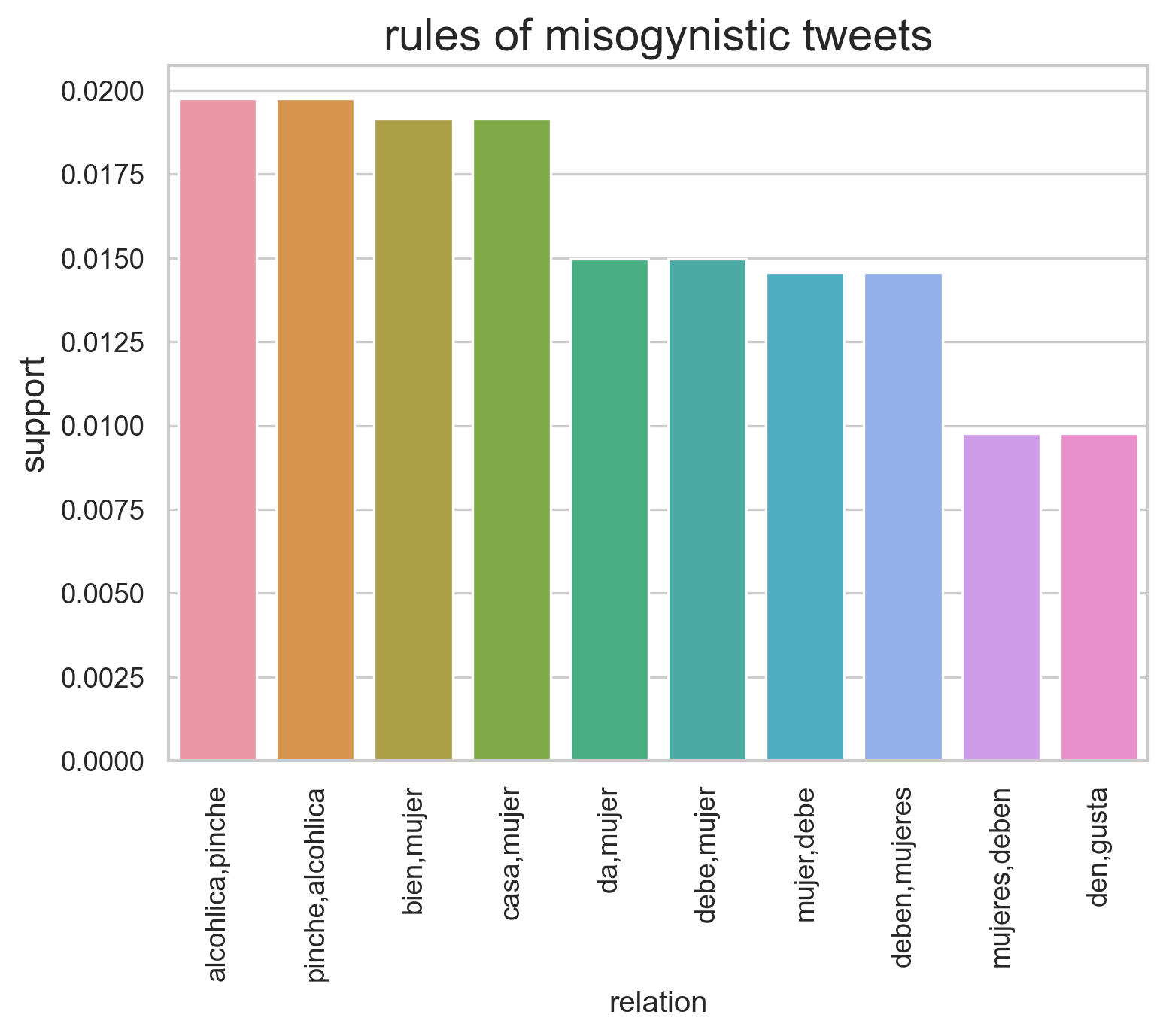
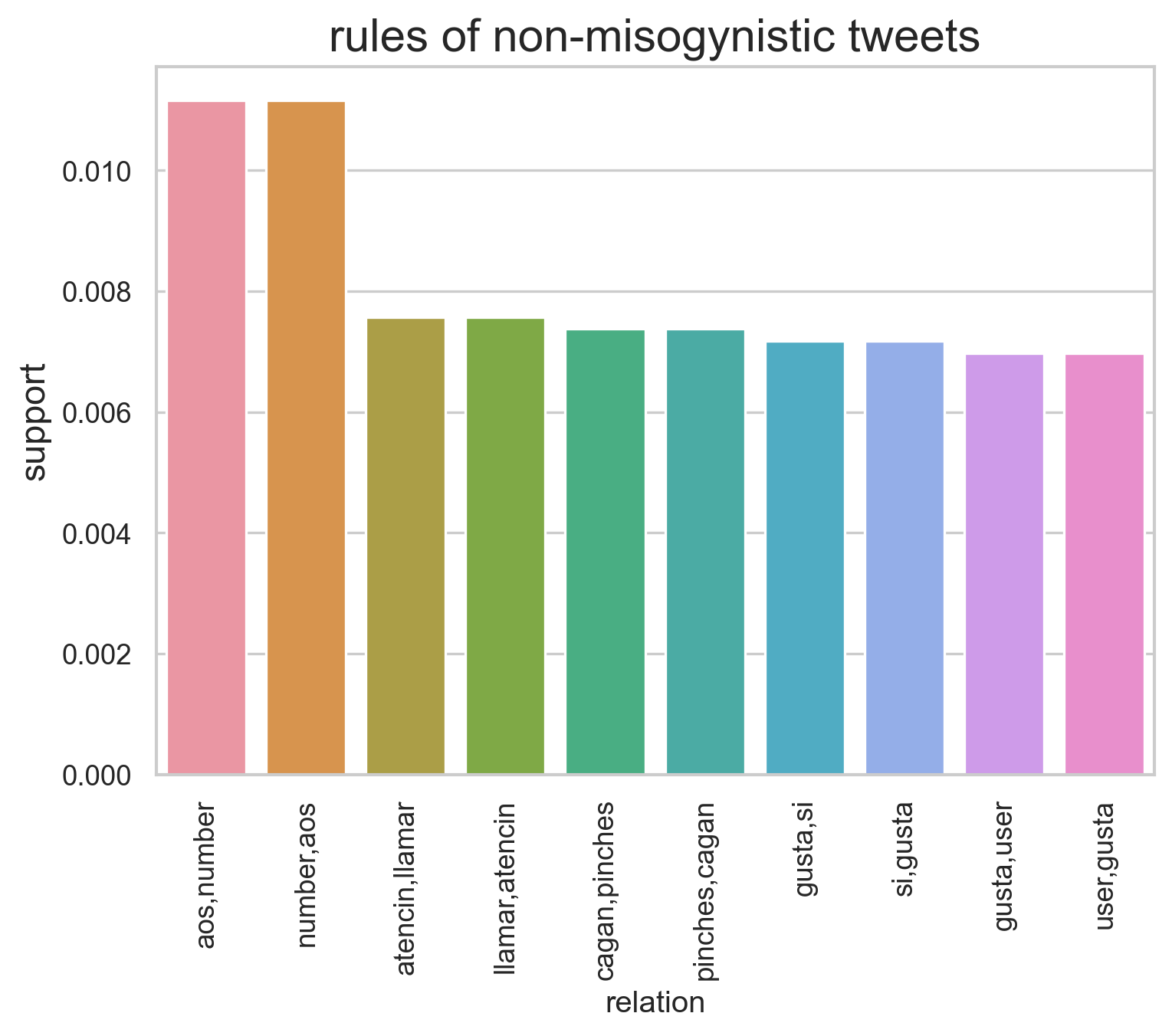
import seaborn as snsrels = (len(miso_results["rhs"]))relation = [str(miso_results["rhs"][x])+","+str(miso_results["lhs"][x]) for x inrange(0,rels)]miso_results["relation"] = [x.replace("'","").replace("[","").replace("]","") for x in relation]miso_results = miso_results.rename(columns={'supp': 'support'})sns.set_theme(style="whitegrid", palette=sns.color_palette("hls", 8))fig, ax = plt.subplots(dpi=120,)ax.set_title("rules of misogynistic tweets", fontsize=18)ax.set_ylabel("support",fontsize=14)plt.xticks(rotation =90)sns.barplot(data=miso_results[0:10], x="relation", y="support")rels = (len(no_miso_results["rhs"]))relation = [str(no_miso_results["rhs"][x])+","+str(no_miso_results["lhs"][x]) for x inrange(0,rels)]no_miso_results["relation"] = [x.replace("'","").replace("[","").replace("]","") for x in relation]no_miso_results = no_miso_results.rename(columns={'supp': 'support'})sns.set_theme(style="whitegrid", palette=sns.color_palette("hls", 8))fig, ax = plt.subplots(dpi=120,)ax.set_title("rules of non-misogynistic tweets", fontsize=18)ax.set_ylabel("support",fontsize=14)plt.xticks(rotation =90)sns.barplot(data=no_miso_results[0:10], x="relation", y="support")
<AxesSubplot:title={'center':'rules of non-misogynistic tweets'}, xlabel='relation', ylabel='support'>
After looking at the relations with higher support, there is a clear difference in words between misogynistic and non-misogynistic tweets.
The relation with higher support for misogynistic tweets was “deber” and “mujeres,” which is translated to women must, so there is a pattern of saying what women should do in misogynistic tweets. The second highest support was for the relation “alcoholic” and “pinche” it is essential to remark that alcoholic is used as a noun and has an “a” termination which means it is referring to an alcoholic female; the word pinche is a slur used as an adjective to emphasize the noun, with this information the assumption is that misogynistic tweets frequently refer to alcoholic women. Finally, a significant relation not shown in the graph is “voy” and “matar,” meaning “Will” and “kill” having tweets with the such combination can be a threat or physicological violence directly to a woman, which demonstrates the importance of this work.
On the other hand, the nonmisogynistic tweets also have relations that might sound misogynistic such as “pinches” and “cagan,” which translates to an adjective and a verb used as a slur to demonstrate being angry.
The ARM model explores a set of data that specially measure how frequently bigrams appear together and how strict that appearance is. It is also important to remember that the appearance of bigrams does not mean a tweet can be classified as misogynistic; for example, if a tweet states, “he said I will kill you,” there is an appearance of the words “will” and “kill” but the tweet is not violent neither misogynistic, although it is talking about violence. Therefore techniques such as ARM should be accompanied by a profound interpretation, and prediction should be performed with a classifier with higher relation techniques—t, negatively, or positively related.